
트랜스포머에 대한 강한 집착
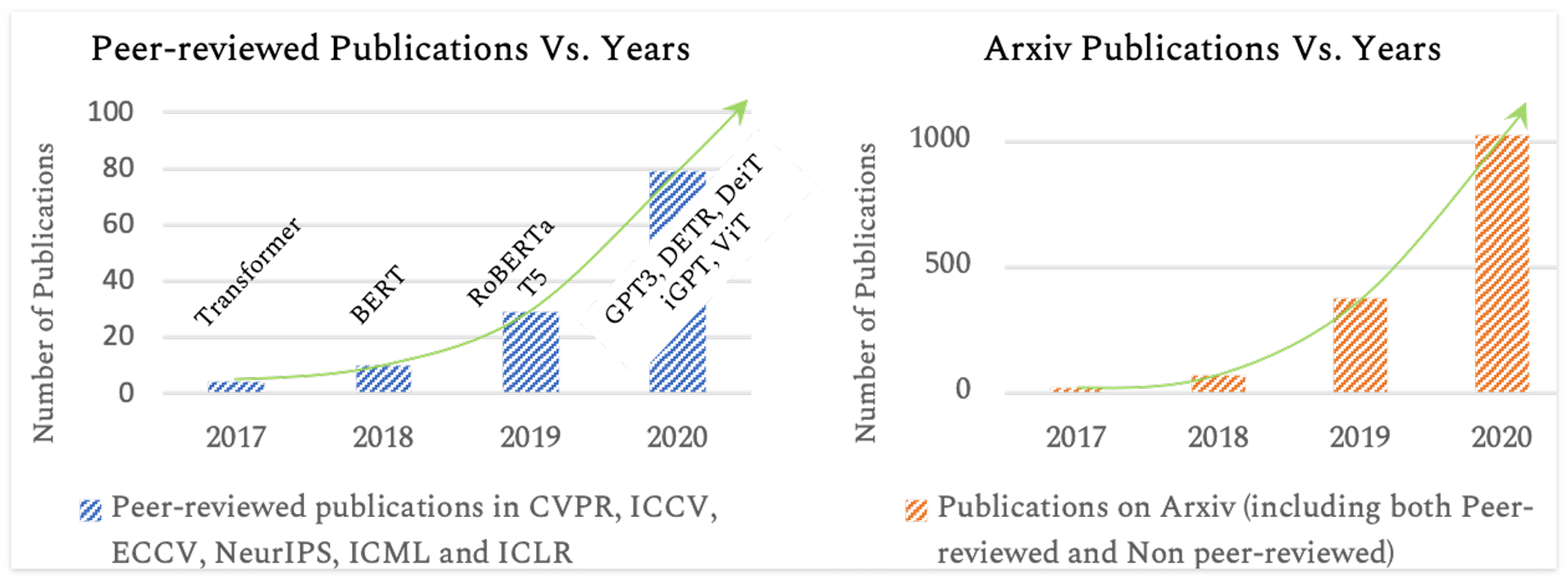
딥러닝이 발달하는 속도가 워낙 빠르다보니, 새로운 모델 구조를 다양한 분야에 적용하는 것은 빈번이 일어나고 있다. 최근에는 트랜스포머가 NLP 를 넘어서 더 넓은 분야에서 사용 되고 있으며, 앞으로 더욱 자주 사용될 것으로 예상된다. 트랜스포머의 장점은 더 많은 정보를 모델이 담을 수 있다는 것이다. Local Receptive Field 와 Transition Equivariance 를 특징으로 하는 CNN 에 비해서 상대적으로 Inductive Bias 가 덜한데, 이는 바꿔말하면 모델이 가지는 자율성이 높다는 것이고 데이터의 구조에 대한 정보를 더 많이 담고 있을 확률이 높다는 것이다. 최근에 ViT(Vision Transformer, 2021 ICLR)와 DT(Decision Transformer, 2021, NeurIPS)가 개발되면서 딥러닝이 쓰이는 더 많은 분야에 트랜스포머 구조가 Foundation model 로 사용되고 있다.
# Vision
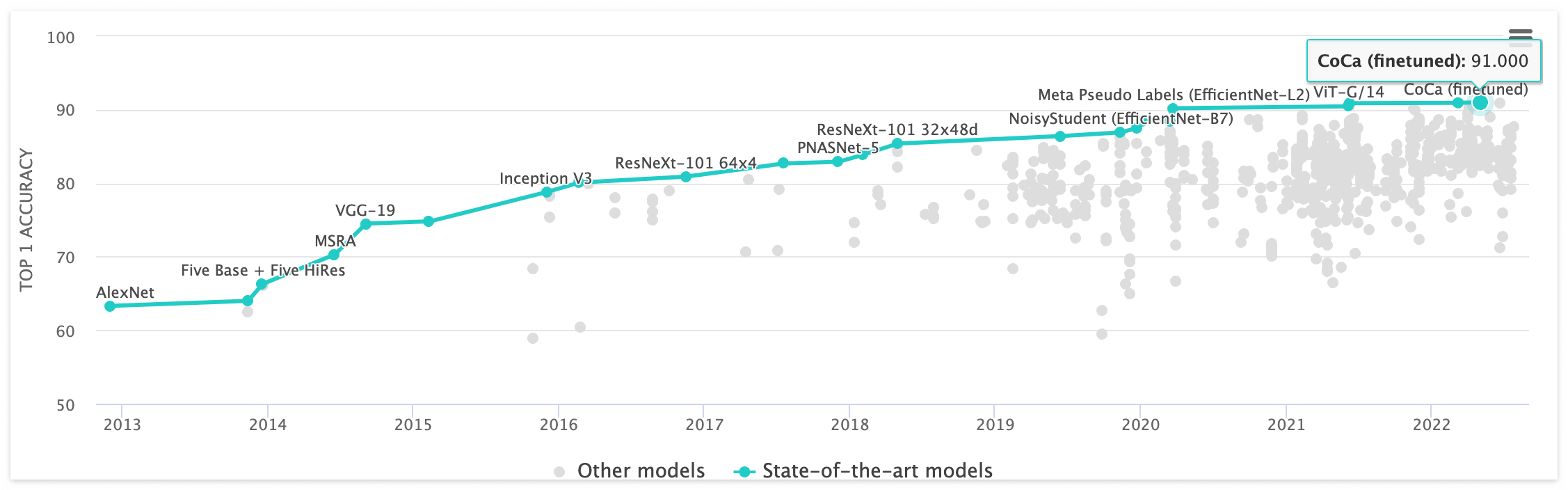
2022년 5월에 발표된 CoCa 모델은 ImageNet에서 91% 의 Top-1 정확도를 보였다. 해당 모델은 Image에 대해서 Text가 가이드된 방식으로 Pretraining을 진행하는데, 텍스트와 이미지에 대해서 모두 Uni-model 을 구조적으로 나타내고 Contrastive Learning을 함으로써, 텍스트와 이미지로 할 수 있는 모든 학습을 진행한다.
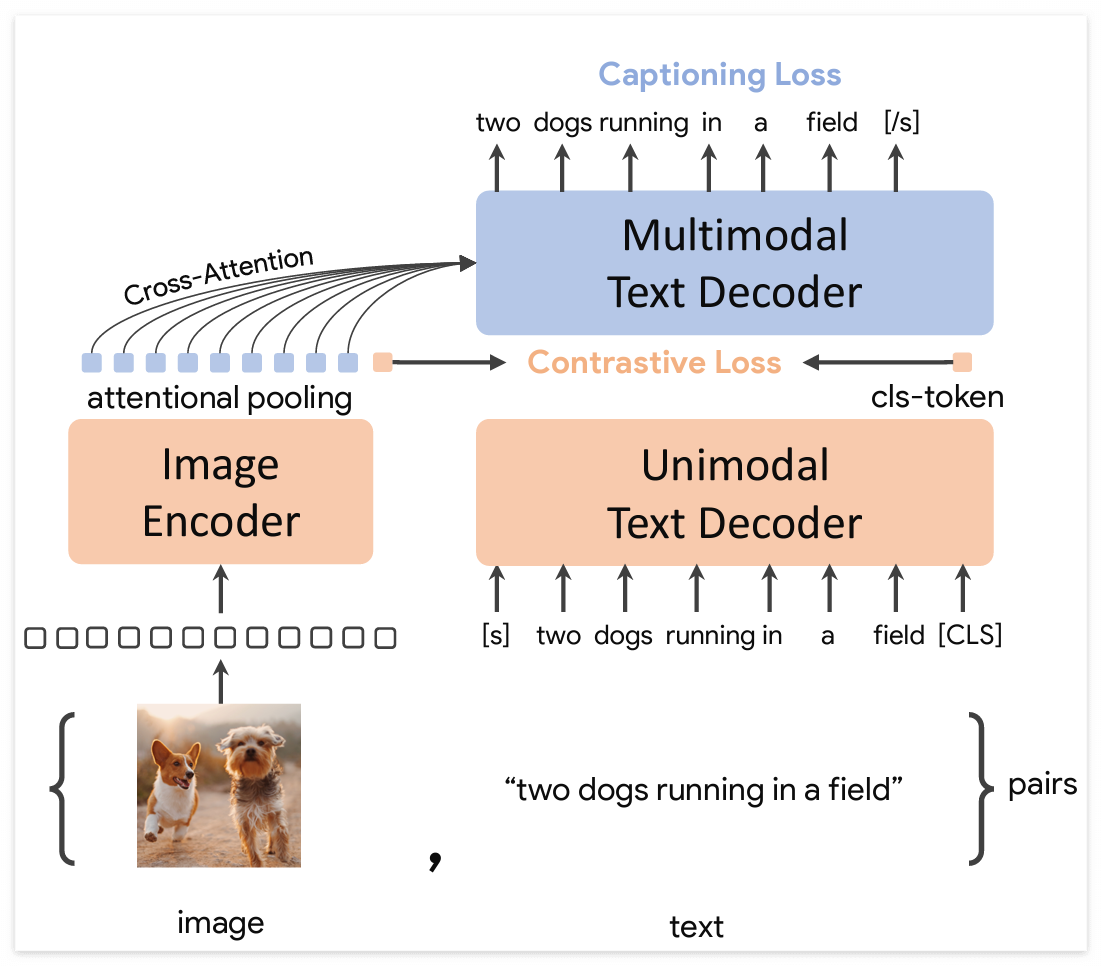
ImageNet에 대해서 Finetuning 할 때는, Query를 재학습시키면서 ImageNet Classification을 가능하게 만들었다. 모델 학습에 대해서 Image자체보다 Text-Guide가 된다면 더 높은 성능을 보인다는 것은 기존에 다른 논문들에서도 보였지만, 해당 논문에서는 사실상 이미지와 텍스트에 대해서 기본이 되는 모든 Self-Supervised Learning 학습 방법을 사용하여 더 높은 성능을 가진다는 것을 보였다.
CoCa https://arxiv.org/abs/2205.01917
ImageNet Rank https://paperswithcode.com/sota/image-classification-on-imagenet
# RL
Decision Transformer 의 경우도 Off-line RL 문제에 대해서 Trajectory Learning을 함으로써, TD-Learning 기반인 CQL (Conservative Q-learning) 보다 일부 Task에서 더 높은 성능을 보였다. 해당 논문에서는 Atari에서는 CQL이 좀더 높았고, Continuous Control (Mujoco) 에서는 DT가 더 높았다. 추가적으로 Key-to-Door 같이 Sparse Reward Setting에서는 DT가 월등히 높은 성능을 보였다. DT가 Self-supervised learning 을 추가로 가능하다는 점을 미루어볼 때, 앞으로 나올 논문들에서는 Atari 보다 더 높은 성능을 내는 Trajectory Learning 방식이 제안될 것으로 보인다.
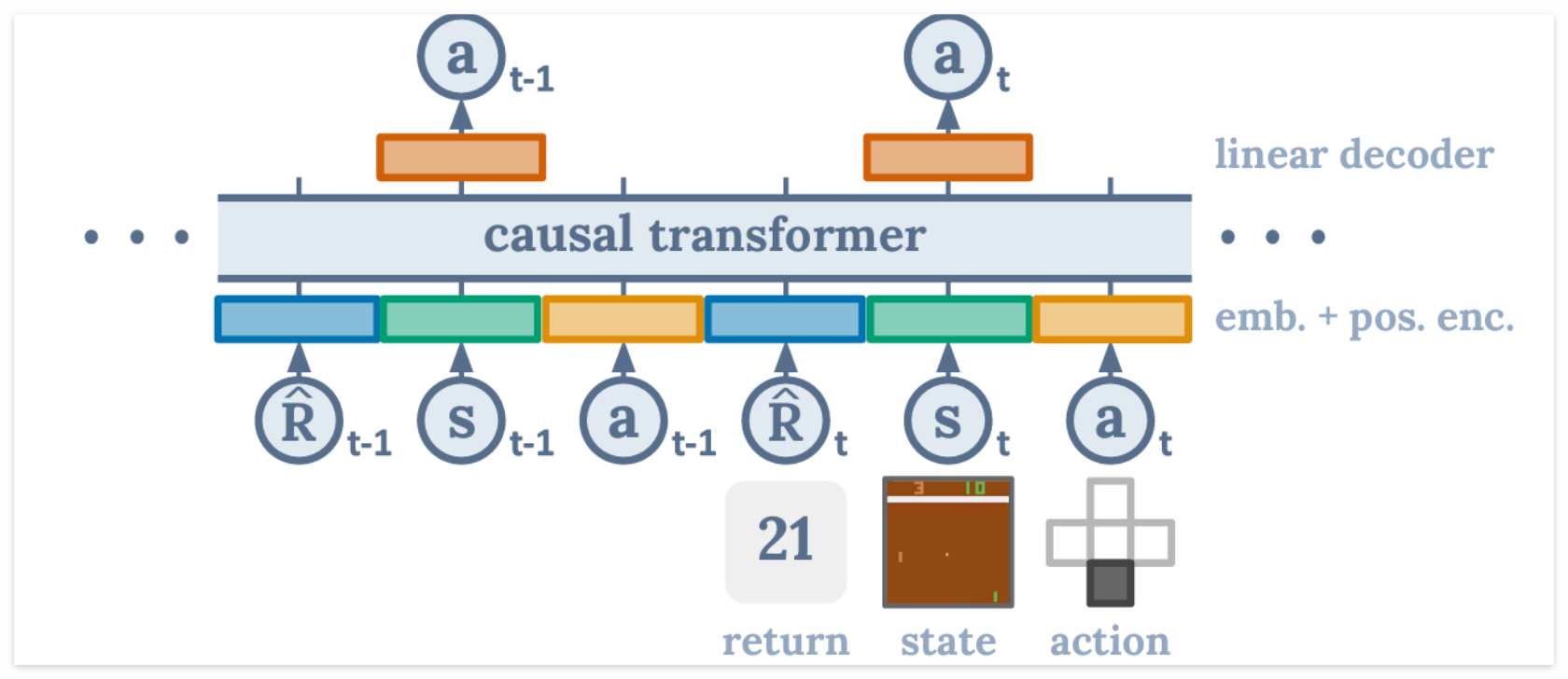
Decision Transformer
https://proceedings.neurips.cc/paper/2021/hash/7f489f642a0ddb10272b5c31057f0663-Abstract.html
# Conclusion
결국 앞으로 Foundation 모델로 Transformer는 더욱 자주 사용될 것이고, Transformer에 대해서 더 많은 해석적인 연구가 필요해 보인다. 일반적으로 Attention Mechanism을 사용하여 Global Receptive Field를 가지므로 해석이 쉽진 않지만, 모델이 가지고 있는 지식에 대한 검수는 반드시 이루어져야 한다고 생각한다. 내가 생각하는 Transformer의 장점은 지식을 저장한다는 것인데, 이는 모델이 모든 input 정보에 대해서 attention을 진행하기 때문이다. 이러한 Transformer의 장점을 고려하지 않는 경우는 Pretraining 없이 Scratch부터 학습을 하는 것인데, 이는 학습 데이터에 대해서 Overfitting된 결과를 가져올 것으로 예상된다.
- 일부 AI 관련된 배경지식이 필요한 글입니다. ✍🏻
- 주관적인 내용이 포함된 글 입니다.
- 더 많은 트랜스포머 구조의 쓰임새에 대해서는 아래 논문을 추천합니다. 🙂
Transformers in Vision: A Survey (https://arxiv.org/abs/2101.01169)
'에세이' 카테고리의 다른 글
| 대학원생의 NeurIPS 2022 컨퍼런스 후기 (2) | 2022.12.05 |
|---|---|
| [연구일지] 존경하던 Müller 교수님을 만나다. (1) | 2022.10.09 |
| 대학원 컨텍 메일 필독 사항 (2) | 2022.01.09 |
| 2021년 생존한 대학원생 경험담 - 1 (2) | 2021.12.21 |
| AI 대학원 면접 준비 - 전공 질문 리스트 (43) | 2021.06.14 |