
[Circuits-CNN] Features, Circuits, and Activations [한국어]
본 글의 내용은 Zoom In: An Introduction to Circuits 을 기반으로 만들어졌습니다.
Feature Visualziation 에 대한 이미지는 위 글에서 가져왔습니다.
1. Introduction
최근 연구들은 신경망을 더 자세히 관찰하여, 모델 내부에 대한 기본단위를 재정의 하는 시도가 있다. 이러한 시도는 생물의 내부를 더욱 자세히 관찰하여 세포에 대한 연구를 진행하는Cellular Biology (세포생물학) 로 부터 영감을 얻었으며, 세포생물학에서 주장한 것과 유사하게, 모델의 기본 요소인 Feature 에 대해서 3가지 기본요소를 주장한다. [link]
1. Feature 는 신경망의 기본 단위이다.
2. Feature 는 연결되어 있다 (Weight 을 통해서)
3. 모든 모델들은 비슷한 Feature를 가진다. (Universality)
2. Features
위에서 언급한 Feature에 대해서 많은 연구들이 그 정의를 제대로 파악하지 못하고 있으며, 일관된 정의가 없다. 내가 이해한 Feature의 정의는 하나의 유닛 (CNN Channel, Attention Head 등) 이 지니고 있는, 본질적인 의미이다.
Feature : the semantic meaning of a unit
예를 들어서, 아래 그림은 InceptionV1 의 CNN 채널이 가장 활성화되는 이미지들을 나타내는데, 각 채널들이 보여주는 정보는 한 쪽에는 Low Frequency 다른 쪽에는 High Frequency 를 지닌다는 것이다. 이런식으로 유닛은 그 의미를 최대화하는 입력의 상태가 존재하며 Feauture 라고 불린다.

2.1 Features : Composition
가정: 신경망은 여러 개의 Feauture 들에 대한 연결로 이루어져 있다.
Interpretability 에서 하는 기본 가정은 모델의 유닛들이 의미를 지니고, 의미들이 연결되어 더욱 복잡한 의미를 만들어 낸다는 것이다. 두 개의 의미를 섞어서 새로운 의미를 만들어 낼 수 있는 것이다.
예를 들어서, 이미지에 대해서 원형 줄무니, 선형 줄무니 등 선에 대한 다양한 형태가 있을 때, 이 정보들을 취합하여 강아지의 털이나 눈을 만들 수 있는 것이다. 아래 그림은 유닛이 지니고 있는 Feature 에 대해서 단 하나의 Feature 를 가진다는 가정 (Monosemantic) 을 한 경우 가능한 예시를 나타낸다. 초반 레이어는 가장 기본적인 패턴들을 가지고 있고, 뒤로 갈수록 복잡한 패턴들이 형성된다.
위 : 3개의 층으로 이루어진 신경망, 각 층에는 3개의 Unit이 존재해서 Feature를 담고 있다.
아래 : 각 유닛이 담고 있는 Feature를 이미지로 표현한 그림이다.
2.2 Features : Transform
하위 레이어에 존재하는 Feature들은 Weight 을 곱함으로써 적절한 방식으로 변형될 수 있다.
이를 다음과 같이, [U] 유닛이 [W] 를 곱함으로써 [V] 가 된다고 표현하자.
[U] → [U] * [W] → [V]
대표적으로 아래 그림과 같이 [U] 상태에 [W] 를 Convolution 으로 곱하면 다음과 같은 [V] 상태가 만들어진다.
(해당 그림은 5x5 convlutional filter 를 가정한다)
기존의 Feature 를 적절하게 변형하여 새로운 Feature를 만드는 것으로, 만일 양수 (+) 값이 있으면, 값을 활성화하는 것으로, 음수 (-) 가 있으면, 값을 줄이는 것으로 해석할 수 있다. 이러한 방식을 흥분 (Excitation) 과 억제 (Inhibition) 이라고 표현한다.
- Excitation (+) : 아래 유닛의 Feature가 전달된다.
- Zero (-) : 아래 유닛의 Feature 에 의존적이지 않는다.
- Inhibition (-) : 아래 유닛의 Feature가 정반대로 전달된다.
3. Circuits
회로는 두 개의 노드 (레이어) 에 존재하는 Subgraph를 나타낸다. 수 많은 하위 레이어의 유닛들은 상위 레이어의 유닛들이랑 연결되어 있으며, 서로 다른 가중치로 연결되어 있다. 이러한 연결 그 자체를 Circuit 이라고 한다. 회로를 해석하는 것은 어려운 과정인데, 분석해야 하는 회로 수가 무수히 많이 때문이다. 모델 내부에는 지수적으로 많은 회로들이 존재하며, 그들의 값 또한 바뀔 수 있기 때문에, 일부 회로들을 이해하는 것으로 모델의 행동을 완벽하게 이해하기는 불가능하다. 그럼에도 불구하고 몇개의 회로들은 해석적으로 접근할 수 있다. [original link]
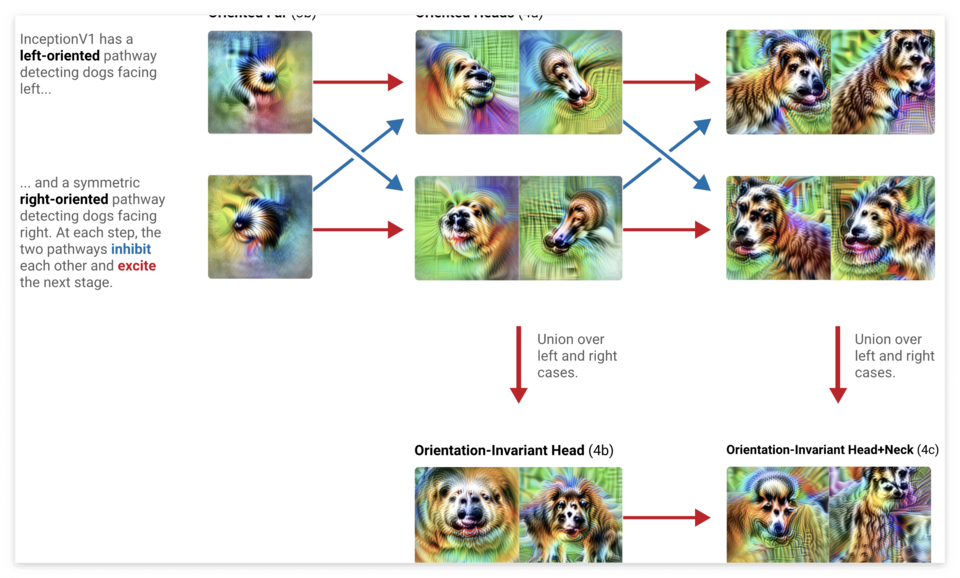
아래 그림은 어떤 식으로 Orientation-Invariant Head + Neck 이 형성되는지 회로로 나타낸 것이다. 총 4개의 레이어를 거쳐서 해당 Feature 가 만들어지는 것을 확인할 수 있다.
Layers : 3b → 4a → 4b → 4c
Features: 털 / 머리 방향 → 머리 → 머리 + 목
4. Activations
Feature 와 Circuit 은 모델의 내부가 지니는 의미를 나타내는데, 이는 사실 입력으로부터 생겨난 정보가 아니다. 즉, 강아지 그림을 넣어서 강아지 Feature 가 생긴 것이 아니라, 유닛이 본래 지니고 있는 의미를 표현한 것이다. 입력에 대한 해석을 위해서는 Activation 과 Representation 이라는 개념이 필요하다.
- Feature and Circuits : 모델의 고유한 정보
- Activation and Representation : 입력으로 인해서 발생한 결과물
입력을 넣었을 때, Feature 가 사용되는 방식은 활성화 값(Activation)을 전달하는 것이다. 이는 해석하자면, Feature를 어느정도 수용하는지 값을 전달하는 것으로 생각할 수 있다. 만일 Activation 이 0 이라면, 해당 유닛이 지니는 Feature 를 미포함 한다는 정보가 전달되는 것으로 볼 수 있다. 아래 그림에서 고양이 얼굴을 넣었을 때 활성화 되는 Feature 들을 확인해보자.
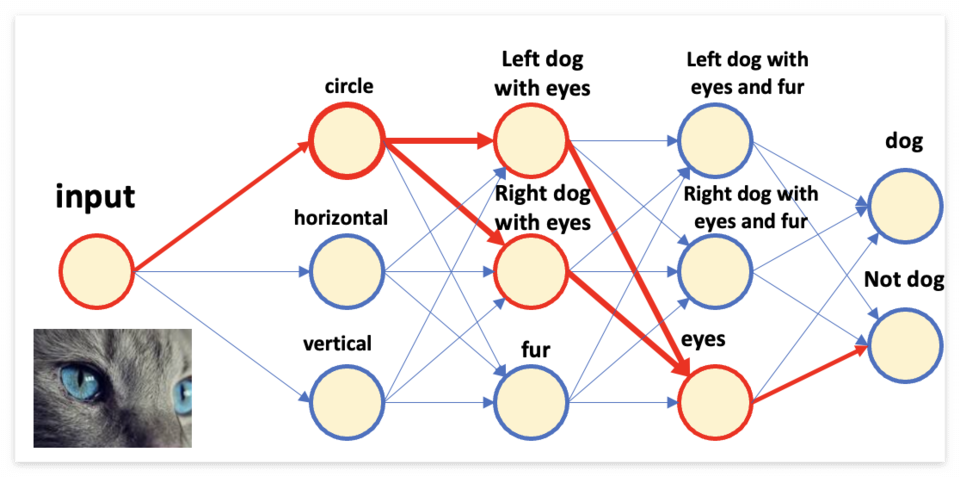
결과적으로 강아지의 머리/털에 대한 정보는 활성화되지 않았고 눈에 대한 유닛만 활성화 되었기 때문에, 잘 학습된 모델이라면 강아지가 아닌 것으로 분류할 것이다.
5. Conclusion
해석의 목표는 일반화된 유닛들을 설명하고, 유닛들의 관계를 밝혀내는 것이다. 유닛들이 모델에 형성되는 방식으로 인해서 모델에서 나타나는 다양한 현상에 대해서 설명할 것을 기대할 수 있다. 실제로 최근 연구들은 Interpretability 를 이용하여 몇 가지에 대해서 합리적이고 논리적인 방식으로 모델을 해석하였다.
Feature 와 Circuit 으로부터 얻을 수 있는 기본적인 형태는 사실 Feature 에 대한 연대기이다. 하위 레이어의 Feature 들로부터 자연스럽게 구성된 상위 레이어의 Feature 를 해석 및 이해하는 것은 계층적인 Feature 의 구조를 설명해줄 수 있다.
Feature 와 Circuit 의 가장 큰 문제는 일관성인데, 모델마다 형성되는 Feature 가 서로 다르다면, 모델마다 다른 해석을 해야 한다. 이를 해결하기 위해서 본 글은 공통적인 특성을 지닌다는 “Universality Hypothesis” 을 세웠고, 이게 어느정도 성립하는 경우, Zoom in 을 통해서 내부를 살펴보는 것이 단순히 모델을 관찰하는 분야를 더 넘어서 Feature 들 간의 상호작용을 연구하는 분야로 발전될 수 있다.