Invariant 와 Equivariant 를 구분하는 방법
TL;DR
Equivariant는 Rotation을 전후로 적용해도 괜찮은 공간들로 한다.
Invariant 는 아웃풋이 아무거나 상관없다. (심지어 스칼라도!)
Intro
딥러닝을 하다보면, Representation에 대해서invariant 또는 Equivariant 라는 단어를 쓸 때가 있습니다. 이는 의미상 굉장히 비슷하기 때문에 쓰임새를 구분하는 것이 쉽지 않습니다. 의미적으로 보면, Invariant : 불변, Equivariant : 동일로 해석할 수 있는데, 의미적으로 두 개를 기억하는 것은 아무런 도움이 되지 않으며, 수식을 외운다고 할지라도 단순히 정의을 기억하는 것 이상의 정보를 주진 않습니다. 그래서 Invariant 와 Equivariant 의 차이를 제대로 보여주는 함수의 인풋과 아웃풋의 관점에서 Invariant 와 Equivariant 를 해석해보고자 합니다.
정의
먼저 정의를 살펴보면 다음과 같습니다.

invariant 와 equivariant 를 다룰 때는 두 개의 함수 $f$ 와 $g$ 가 나오며, 보통 $g(x)$ 가 $x$ 를 변형한 형태를 나타냅니다(이미지 회전이나 슬라이딩 이동 등). $g$-invariant 하다는 표현은, 함수 $f$가 $g$의 변환에 대해서 아웃풋이 바뀌지 않는 성질을 나타냅니다. $g$-equivariant 의 경우는 $g$ 의 변환에 대해서 $f$ 를 적용하는 순서에 대해서 아웃풋이 동일한 성질을 나타냅니다. 성질은 동일해보이지만, Invariant 와 equivariant 가 성립하기 위해서는 함수 공간에 대해서 서로 다른 제약사항을 가지고 있습니다.
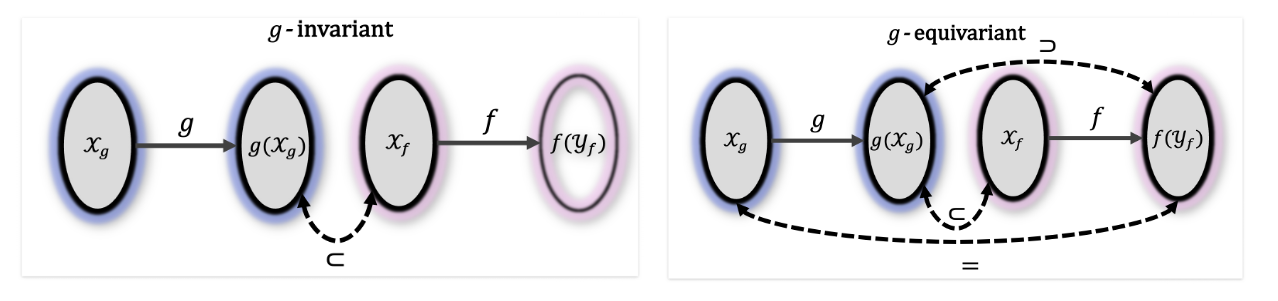
Invariant & Equivairant 정의역과 공역
$g$-invariant $\Big(f(g(x)) = f(x)\Big)$ 와 $g$-equivariant $\Big((f(g(x)) = g(f(x))\Big)$ 가 성립하기 위해서는 두 함수 $f$ 와 $g$의 정의역과 공역에 대해서 적절한 매칭이 필요합니다. 이퀄리티 (A=B) 가 성립하려면 어쨌든 A, B는 동일한 공간에 속해야 하기 때문입니다. 가령, 이미지 예측 문제에서 이미지 공간 샘플 $x_1 \in R^{H\times W\times C}$ 는 네트워크 아웃풋 공간 샘플 $x_2 \in R$에 대해서 $x_1 = x_2$ 라고 식을 절대 세울 수 없습니다. 애당초 둘은 비교 불가능 합니다.
Invariant
먼저 Invariant 가 성립하기 위해서는 $g(x)$ 가 $x$ 와 동일한 공간에 놓여야 합니다. 그래야 $f(g(x)) = f(x)$ 라는 식이 성립할 수 있습니다. 이로부터 다음과 같이 Proposition이 성립합니다.
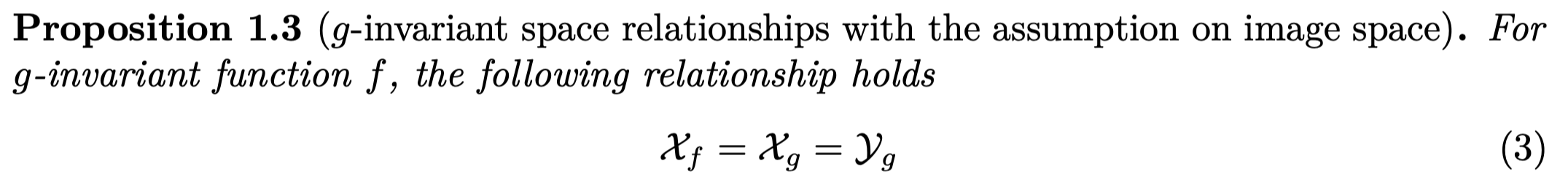
그림으로 나타내면 아래와 같습니다. 함수 $g$ 와 $f$ 의 정의역과 공역에 대해서 $\mathcal{Y}_g$ 와 $\mathcal{X}_f$ 가 서로 동일한 공간이어야 합니다.

해석하자면, $g(x)$ 는 반드시 $x$랑 동일한 공간에 있어야 합니다. 그런데, $f(x)$ 가 어떠한 공간에 놓여야 하는지는 전혀 가정이 없습니다. 이는 이미지로 치면, 다시 이미지 공간일수도 있고, 스칼라일수도 있습니다. 그러므로 invariant는 아웃풋을 마음대로 설정할 수 있습니다. 아래 그림과 같이 $Y_f$ 의 공간이 기존 정의역과 같은 경우와 다른 경우를 마음대로 성질할 수 있습니다.

Convolution Neural Network 에서
1) 이미지를 모델에 넣고 Convolutional Representation 을 확인
2) 이미지를 회전 하고 모델에 넣고 Convolutional Representation 확인
두 Representations 가 동일 <- Invariant
극단적으로 말해서, invariant 에서는 $f$의 아웃풋이 단순히 스칼라일 수도 있습니다. 가령, 모델이 모든 이미지에 대해서 강아지라고 예측한다면, 이 경우도 invariant 라고 말할 수 있습니다.
Equivairant
그러나 Equivariant 가 성립하기 위해서는 아웃풋 공간은 인풋 공간과 같아야 합니다. Equivraint $f(g(x)) = g(f(x))$ 가 성립하기 위해서는 $f$ 와 $g$ 의 정의역과 공역이 모두 같은 공간이어야 합니다. 왜냐하면 $g$ 의 인풋이 $f$의 아웃풋과 같은 공간에 있어야 하고, $f$의 인풋이 $g$와 같은 공간에 있어야 하기 때문입니다.


아래 그림과 같이 두 개의 연산에 대해서 Commute 하는 성질이 있어야 합니다. $g$ 아웃풋이 $f$의 인풋과 동일하며, $f$의 아웃풋과도 동일합니다. 단순하게 말하면, 아래그림에서 $f$ 의 아웃풋은 Rotation Operation이 되는 공간입니다.
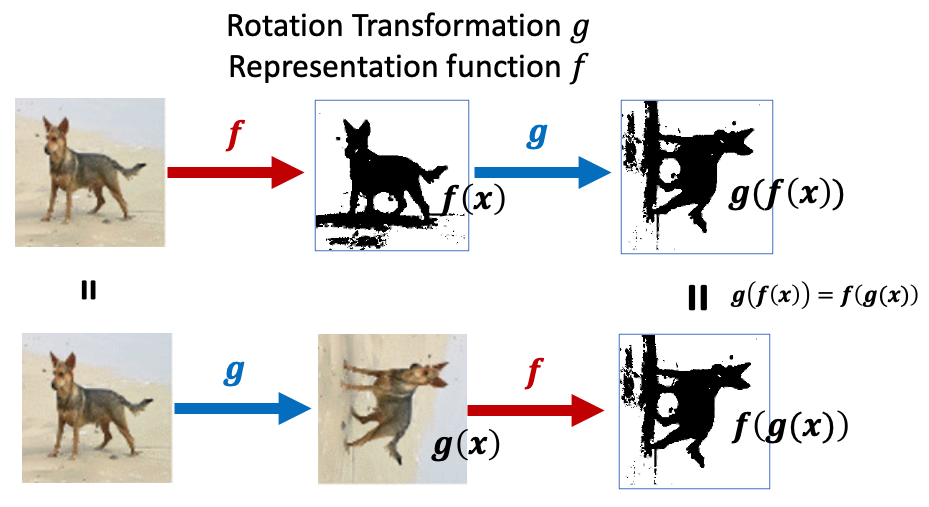
예시 )
Convolution Neural Network 에서
1) 이미지를 모델에 넣고 Convolutional Representation 을 회전
2) 이미지를 회전 하고 모델에 넣고 Convolutional Representation 획득
3) 두 Representations 가 동일 <- Equivariant
+ CNN의 경우, Convolutional Layer의 연산으로 이미지 공간이 줄어들 수 있으나, Translation (픽셀 위치 옮기는 연산)을 전후로 해도 아웃풋이 동일하기 때문에 Translation-Equivariant 가 성립합니다. 그러나 마지막 Feature Space 에 대해서는 Translation을 시켜도 아웃풋이 동일하지 않기 때문에 전체 모델에 대해서 Translation-Equivariance 가 성립하진 않습니다. 마지막 레이어에 대해서 이미지에 Translation 을 해도 동일한 Feature를 얻는다면, Translation-Invariant 라고 말해야 합니다.
Adavanced
사실 수식적으로 더 엄밀하게 말하면, 함수 $g$ 로 변형된 공간은 $X_f$ 와 동일하지 않을 수 있습니다. 대신 $g(X_g)$ 가 $X_f$ 의 부분집합으로 작용할 수 있습니다. 이 부분에 대한 설명은 넘어가겠습니다.
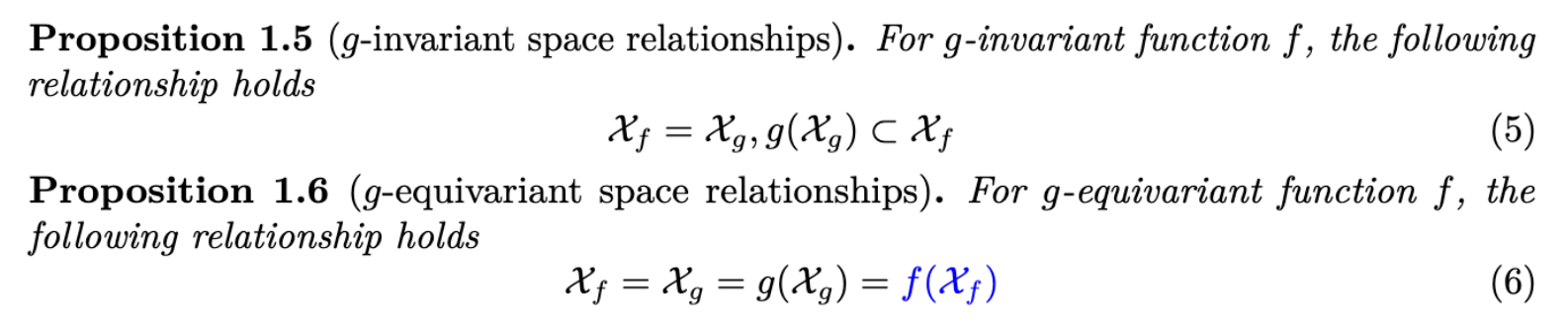
Conclusion
Equivariant는 Rotation을 전후로 적용해도 괜찮은 공간들로 한다.
Invariant 는 아웃풋이 아무거나 상관없다. (심지어 스칼라도!)
이렇게 외우시면 논문을 읽으시면서, 그 의미를 좀더 쉽게 해석할 수 있는 것 같습니다.