
Reinforcement Learning - Skill Discovery [스킬을 배우자] 중요한 것은 Mutual Information!
Too Long ; Dont Read
스킬별로 상태를 연관짓자. Mutual Information으로 모델링할게, 딥러닝 알아서 해줘!
INTRODUCTION
강화학습은 환경에서 에이전트를 학습하는 학습 방법으로 딥러닝 이후 꾸준하게 발전한 분야입니다. 에이전트는 주어진 상태에 대해서 미래에 받을 보상까지 고려해서 최적의 행동 시퀀스를 생성하도록 학습됩니다. 딥러닝을 이용해서 자동적으로 학습할 수 있으나, 모델은 순간적인 상태에 대해서 행동을 결정하므로, 행동 시퀀스에 대해서 연속된 패턴을 만들어내지 못할 수도 있습니다. 가장 큰 이유는 Policy $\pi(a|s)$ 가 확률적이기 때문에, 에이전트는 상당히 불확실한 행동들을 하기 때문입니다.
이보다 좀 더 나은 방법은 주어진 상태에 대해서 스킬에 대한 정보를 같이 주고 행동을 학습하는 $\pi(a|s,z)$ 형태로 행동을 학습하는 것입니다. 현재 상태 $S$ 뿐만 아니라 스킬 $Z$ 까지 주면서, 에이전트의 행동에 대한 일관성을 줄 수 있고, 이는 실제로 로봇의 컨트롤과 같은 곳에서 사용됩니다. 스킬 $Z$ 를 인코딩하는 방식에 대해서 다양하게 연구되어 왔고 여기서는 CS330의 강의내용을 바탕으로 정리해보겠습니다.
스킬 $z$ 와 연관지어서 상태와 행동을 학습하는데 있어서, 가장 중요한 개념인 Mutual Information 을 이해해야 합니다.
Mutual Information은 두 개의 Random Variable이 얼마나 관련성이 있는지를 나타내는 지표로, 하나의 값이 주어졌을 때 나머지를 쉽게 예측할 수 있다면 MI 값이 높다.
가령, 날씨와 자전거의 경우, 두 개는 일정부분 연관성이 있으므로 MI 값이 높다고 할 수 있습니다다. 비슷하게 스킬에 대해서 State $s$ 가 연관성이 높다면, $I(Z,S)$ 는 높은 값을 지니게 된다. 특정 상태에서 및 스킬에 대하여 연관성을 높이는 것이므로 결국 $I(Z,S)$ 를 높이는 방향으로 모델링을 하게 됩니다.
포스팅에서는 세 가지 개념/알고리즘에 대해서 다룹니다.

세 가지의 공통점은 모두 Mutual Information을 모델링한다는 점이고, 차이점은 연관짓는 랜덤변수가 다르다는 것입니다. Empowerment 를 이해하고 나면, 스킬의 중요성을 좀더 이해할 수 있지만, 단순히 스킬 부분을 읽고 싶다면, Empowerment 를 건너뛰는 것을 추천합니다.
Empowerment (권한)
Empowerment (권한) 라는 단어는 에어진트가 환경에 대해서 얼마나 통제력을 가지고 있는지 나타냅니다. 에어전트가 환경에 대하여 높은 통제력을 가지고 있을수록 Empowerment가 높다고 이야기 합니다. 대부분의 환경은 행동으로 인해서 다음 상태가 고정적이지 않으므로 Empowerment 가 낮습니다. 에이전트가 행동으로 시스템의 다음 상태를 쉽게 예측할 수 있는 경우, 환경에 대한 권한을 가지므로 Em 이 높다고 이야기 합니다. 다음 상태에 대한 통제력 뿐만아니라 n-step 에 대한 통제력을 계산하는 경우, n-step Empowerment 라고 이야기 합니다.
예시) 내가 왼쪽방향으로 가면 친구가 손을 들고 있다. (Em 높다. )
예시) 내가 왼쪽방향으로 가면 친구가 손을 들고 있을 수도 있고, 발을 들고 있을 수도 있다. (Em 낮다. )
Paper : Empowerment for Continuous Agent-Environment Systems
Empowerment 의미
Empowerment 는 Agent 가 환경에 끼칠 수 있는 부분에 대한 영향력
<-> 행동에 의해서 다음 상태가 얼마나 결정되는가?
<-> 행동에 의해서 다음 상태가 결정적(Deterministic) 이면, Empowerment 는 높다.
에이전트가 환경에 대해서 Dynamics의 불확실성을 최대한으로 제거하는 것은, 다음 상태와 행동에 대한 Mutual Information $I(S_{t+1};A)$ 을 최대화하는 행동 시퀀스를 고르는 것과 동일합니다. 여기서 Mutual Information은 행동에 대한 분포인 $P(A)$ 에 따라서 값이 바뀌게 되는데, Empowerment $C(x)$ 는 이를 최대화 한 값인 셈입니다. 보통 강화학습에서 사용하는 Reward에 대한 개념은 포함되어 있지 않고 무관합니다. RL과 비교한다면, RL에서는 Reward를 최대화하는 Optimal Policy 를 다루지만, Empowerment 에서는MI를 최대화하는 Policy를 다룹니다.
Empowerment 는 Mutual Information의 최대값이므로, 다음과 같은 부등식이 성립합니다.
$$I(X';A|x) \le C(x)$$
아래 예제를 보면, 간단한 경우 MI 와 Em을 비교한 결과를 볼 수 있습니다. 다음 표는 Uniform Action P(A) 에 대한 Mutual Information 과 MI를 최대화는 P(A)로 구한 Empowerment C(X) 를 구한 결과를 보여줍니다. 당연히 Em이 IM보다 큽니다.
결론: 사실 둘이 크기는 비슷합니다. 그러나 Policy는 Reward 를 최대화하게 고르므로, 환경의 통제를 최대화하지 않을 수 있고, 반대로 Sparse Reward인 경우, 통제력이 높은 행동을 고를 수 있습니다.
예시) 왼쪽은 어두운 동굴, 오른쪽은 밝은 들판, 그러나 동굴로 가야 보물을 발견 → 낮은 Em, 높은 Reward
예시) 왼쪽은 어두운 긴 동굴, 오른쪽은 밝은 들판, 동굴로 갔으나 Search Space가 크기에 보물 발견 확률 낮음.
Empowerment 를 복습해보면, 다음상태와 현재 행동에 대한 상호정보를 모델링하는 방식이었습니다. 행동으로 환경을 컨트롤할 수 있다는 것은 상호정보량 관점을 보여주지만, 스킬을 배우는데는 크게 관련이 없습니다. 스킬을 배우기 위해서는 스킬을 지칭하는 변수 $Z$ 가 추가적으로 필요합니다. 스킬에 대해서 인코딩하는 Diversity is All You Need (DIAYN) 을 살펴보겠습니다.

Diversity is All You Need (DIAYN) [Paper]
먼저 스킬을 어떠한 변수와 연관 지을지 골라야 합니다.
$$ I(Z;A) \text{~vs~} I(Z;S)$$
첫 번째는 행동에 대해서, 두 번째는 상태에 대해서 스킬 변수를 연관지었습니다. 행동과 스킬을 연관지으면 에이전트가 하는 행동은 스킬 변수에 의해서 크게 좌우됩니다. 만일 5가지 스킬이 있다면, 스킬로 인해서 행동이 제약되며, 상태와 행동의 연관성은 떨어지게 됩니다. 예를 들어서,
달리기 스킬과 걷기 스킬 / 행동 (허벅지, 종아리, 팔, 다리 앞뒤로 움직이기)
가정 1: 행동과 달리기 스킬 크게 연관된다.
가정 2: 행동과 걷기 스킬 크게 연관된다.
이 예시의 경우, 행동은 두 가지 스킬 모두와 크게 연관될 수 없습니다. 하나의 행동에 두 스킬 모두 Mutual Information이 높은 경우, 행동에 의해 스킬이 결정되지 않습니다. 이는 연관성이 높다는 가정에 위배됩니다. $I(Z;A)$ 가 높기 위해서는 다음과 같이 스킬에 대해서 서로 다른 행동을 줘야 합니다.
달리기 스킬과 걷기 스킬 / 행동 (허벅지, 종아리, 팔, 다리 앞뒤로 움직이기)
가정 1: 행동과 달리기 스킬 크게 연관된다. --> 행동 (허벅지, 팔)
가정 2: 행동과 걷기 스킬 크게 연관된다. --> 행동 (종아리, 다리)
물론 이러한 방식으로 행동을 제약하는 것은 강화학습에서 학습 불가능합니다. 그러므로 스킬을 행동과 연관짓는 $I(Z;A)$ 를 계산하는 방식은 틀렸습니다. 이제 $I(S,Z)$의 당위성을 살펴보겠습니다. 아래 그림은 DIYAN 논문에서 스킬에 대해서 벽을 통과 후 에이전트 상태를 시각화하였습니다. 스킬에 대해서 서로 다른 상태들이 나타나고, 이는
스킬을 안다면, 상태를 예측할 수 있습니다.
상태를 알면, 스킬을 예측할 수 있습니다.
그러므로 $I(S,Z)$ 는 높게 됩니다.
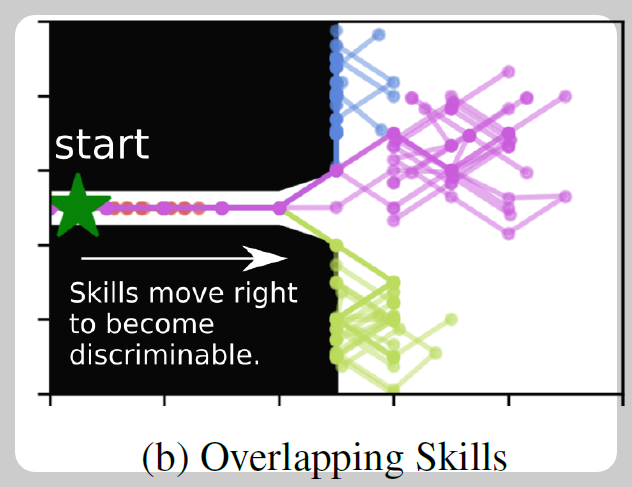
결국 강화학습에서 정의하는 스킬은 변수 $Z$ 와 상태 $S$ 를 연관지어서 나타냅니다. DIAYN 논문에서는 Mutual Information 식을 전개해서 $I(Z,;S)$ 를 최대화하는 변수를 찾습니다.
$$\begin{align}
I(z,s) &= H(z) - H(z|s) \\
&= \underbrace{-\sum_z p(z) \log p(z)}_{\text{diverse skill}} + \sum_z \underbrace{p(z,s)}_{\text{intractable}} \underbrace{\log p(z|s)}_{\text{maximize}}
\end{align}$$
첫 번째 텀, $Z$ 에 대한 엔트로피가 클수록 정보량은 커집니다. 그러므로 우리는 최대한 엔트로피가 큰 $Z$ 를 선택해야 합니다. 두 번째 텀은 컨디셔널 엔트로피를 나타내는데, 두 개로 쪼갤 수 있습니다. 상태 $s$ 에 대한 $z$ 의 Likelihood $p(z|s)$ 가 모델링 되어있으므로, 이를 최대화한다면, 적어도 전체식을 최대화할 수 있을 것 입니다. 따라서 본 논문에서는 다음과 같은 보상을 설정합니다.
$$\begin{gather}
r(s,z) = \log p(z|s) \\
\pi(a|s,z) = \arg\max_\pi \sum_z \mathbb{E}_{s\sim \pi(s|z)} [r(s,z)]
\end{gather}$$
결국 상태 $s$ 에 대해서 연관된 $z$ 의 확률을 높임으로써, 상호정보량을 최대화합니다. 그 결과로 위 그림과 같이 스킬별로 상태가 인코딩 됩니다. 여기까지는 수식적인 내용이고 실제 구현에서 Likelihood $p(z|s)$ 를 어떻게 구현하는지 살펴보겠습니다.
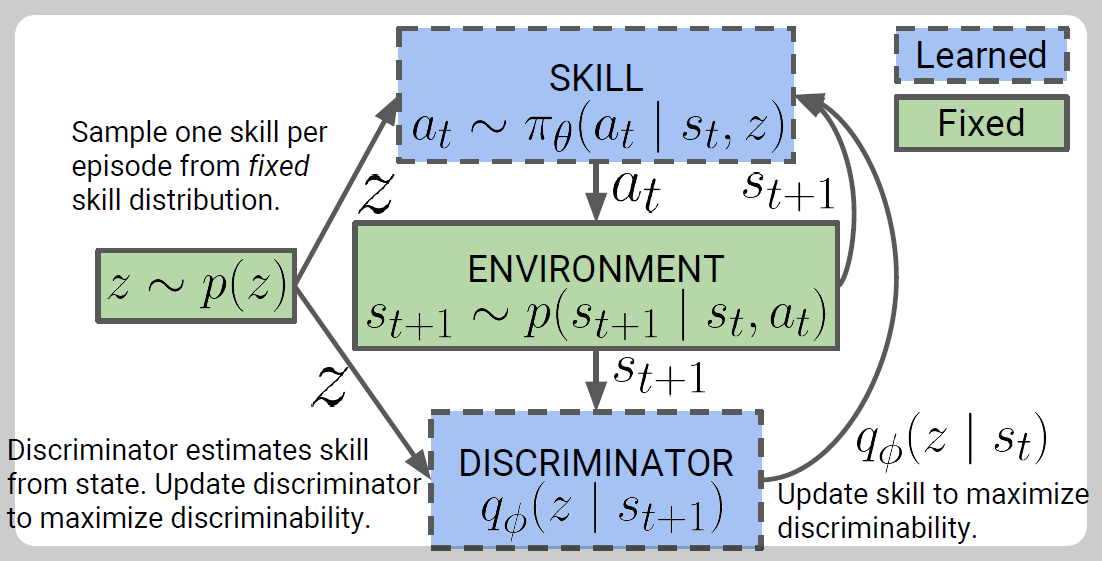
1. 먼저 스킬 z 를 대충 뽑는다.
2. 행동을 $\pi(a|s,z)$ 로 고른다.
3. 환경을 돌린다.
4. Discriminator 가 위에서 뽑은 z에 대한 확률을 준다.
1. 스킬 뽑기
사실 대충 뽑기라는 말은 틀리기, 사용자는 적당한 Prior를 설정할 수 있습니다. 가령 스킬을 3개 [0,1,2] 로 설정하고 확률을 [1/4, 1/2, 1/4] 로 설정할 수 있습니다. 보통은 Uniform Prior 를 많이 사용합니다.
2. 스킬과 상태에 의존적인 행동
스킬을 랜덤하게 뽑는데, 학습이 되는 이유는 스킬에 의존적으로 행동을 하기 때문입니다. 그러므로 동일한 상태일지라도 스킬에 의해서 서로 다른 행동이 나오게 됩니다. 위 그림에서 입구에서 서로 다른 방향으로 나아가는게 그 이유입니다. $\pi(a|s,z)$ 이기 때문입니다.
4. Discriminator
각 에피소드 마다 $z$ 를 뽑기 때문에, 우리는 환경에서 사용된 $z$ 를 알고 있습니다. 강화학습에서 학습하면서 MNIST 숫자 예측처럼 사용된 $z$ 를 예측하는 방향으로 학습이 됩니다.
실제 알고리즘은 단순히 $I(S;Z)$ 뿐만아니라, 행동에 대한 엔트로피를 높이고, 상태에 대한 행동과 스킬의 상호정보량을 줄이는 방식으로 Objective를 설정하였습니다.

이로부터 보상은 다음과 같이 설정됩니다.
$$r(s,z) = \log p(z|s) - \log p(z) $$
$\log p(z)$ 의 역할은 더 확률이 높은 $z$ 에 대해서 패널티를 주는 것 입니다. 해당 텀이 없으면, 결국 모델은 확률이 높은 $z$ 만 주구장창 선호할테니까요.
DIAYN가 일반적인 상태와 스킬에 대해서 연관지었다면, 마지막으로 볼 것은 스킬과 다음 상태에 대한 Mutual Information $I(s_{t+1}; Z)$ 입니다. Dynamics-Aware Discovery of Skills (DADs) 를 살펴보겠습니다.

Dynamics-aware discovery of skills (DADs) [Paper]
스킬의 정의에 대해서 좀더 고심해보면, 스킬이 단순히 연속된 행동을 나타내지만은 않습니다. 아래 그림을 보면, 공(달)이 움직이는 것을 확인할 수 있고, 정지된 상태에서 그 다음에 어떠한 상태가 될지 추측할 수 있습니다.

스킬이라는 것은 단순히 상태와 $Z$ 의 예측성 관계성이 아니라,
스킬과 현재 상태가 주어졌을 때, 다음 상태까지 예측할 수 있어야 한다.
위 아이디어로부터 고려되는 대상은 아래 Conditional Mutual Information이 됩니다.
$$\begin{equation}
I(s',z | s) = H(s'|s) - H(s'|s,z)
\end{equation}$$
이를 모델링 하기 위해서 $q_\phi (s'|s,z)$ : Latent Conditonal Transition Dynamics 모델이 필요하며, 이는 Ground Truth Transition $p(s'|s)$ 와 관련이 있습니다. 모든 스킬에 대해서 확률을 더하면, 원래 Transition과 비슷하게 만들어야 합니다.
$$\begin{equation}
p(s'|s) \approx \sum_i^L \frac{1}{L} q_\phi(s'|s,z_i)
\end{equation}$$
Mutual Information에 대한 LowerBound를 잘 계산하면 다음과 같은 식을 얻고, $q_\phi$ 가 있는 부분을 최대화해주면 됩니다.
$$\begin{align}
I(s';z|s) &\ge \mathbb{E}_s \mathbb{E}_z \mathbb{E}_{p(s'|s,z)} \log \frac{q_\phi(s'|s,z)}{p(s'|s)} \\
&\approx\mathbb{E}_s \mathbb{E}_z \mathbb{E}_{p(s'|s,z)} [\log \frac{q_\phi(s'|s,z)}{\sum_{i=1}^L q_\phi(s'|s, z_i) }+ \log L]
\end{align}$$
예측력을 높이는 것이기에, 강화학습을 진행하면서, DIAYN 처럼 Transition Model $q_\phi$ 를 학습해나가면, 스킬이 학습됩니다.
강화학습에서 스크래치로부터 모델을 학습하는 것은 굉장히 넓은 State Space 와 Action Space를 고려하면 비효율적입니다. 이에 대한 대안으로 여러 스킬을 잘 학습하고, 학습된 스킬들을 조합하여 학습하는 방식이 특히나 로봇 관련 분야 RL에서 사용된다고 합니다. 스킬은 행동이 아니라 상태를 관점으로 봐야 하며, Mutual Information을 높이는 방식으로 연관성을 주는 것이 수식적으로/실험적으로 타당함이 많이 알려졌습니다. 해당 포스팅으로 스킬에 대한 이해가 좀더 있기를 기대합니다. 감사합니다. :)