
Image Copyright: https://distill.pub/2016/deconv-checkerboard/

1. Introduction
Generative Model 의 가장 대표적인 형태는 Convolution 을 지나서, Deconvolution 으로 이미지를 생성하는 것이다. 이러한 구조는 중간에 Bottleneck에 응축된 정보를 가지고 데이터에 대한 특징을 집약적으로 표현하는 특징이 있다. Convolution 단계에서 이미지에서 의미있는 정보들을 추출하며 Spatial 한 부분에 대하여 정보를 가져오는 역할을 하고, Deconvolution에서는 다시 더 넓은 범위로 이미지를 확대하면서 생성을 진행한다. 그러나, Deconvolution 방식들은 Checkerboard 를 형성하는 Artifact 를 가지고 있는데, 이는 강하고 약한 정보들이 반복되는 High Frequency 정보를 생성하는 것이다. 이러한 형태가 데이터의 분포에 대한 정보라면 자연스럽겠지만, 이는 모델의 구조로부터 발생하는 Inductive Bias 로 모델을 의도치 않게 체크보드 형태를 만들도록 형성하는 것이다.
이 글에서는 모델이 체크보드 형태를 생성하는 이유를 살펴보기 위해서, Convolutional Layer에서 연산을 진행하는 방법과 Deconvolutional Layer에서 연산을 진행하는 방법을 비교한다. 연산으로써 체크보드가 생길 수밖에 없는 이유를 살펴보고 저자들이 제안하는 Resize Convolutional 에 대해서 살펴본다.
2. Convolution and Deconvolution
먼저 Convolution 과 Deconvolution 연산을 살펴보자.
Convolution 은 입력에 대해서 필터를 겹침으로써 아래 그림과 같이 계산된다.
Figure: (좌)
Convolution Operation (Kernel=3, Stride=1)
1~7 픽셀들에 대해서 [1,2,3] 벡터를 Convolution으로 계산한다.
Convolution 연산이므로, 픽셀값을 모으는 효과가 있다.
(Matrix) : 각 픽셀 위치별로 값이 얼마나 중첩되는지 나타낸다.
Figure: (우)
DeConvolution Operation (Kernel=3, Stride=1)
1~5 픽셀들에 대해서 [1,2,3] 벡터를 Deonvolution으로 계산한다.
Convolution 의 역 연산이므로, 픽셀값을 퍼트리는 효과가 있다.
(Matrix) : 각 픽셀 위치별로 값이 얼마나 중첩되는지 나타낸다.
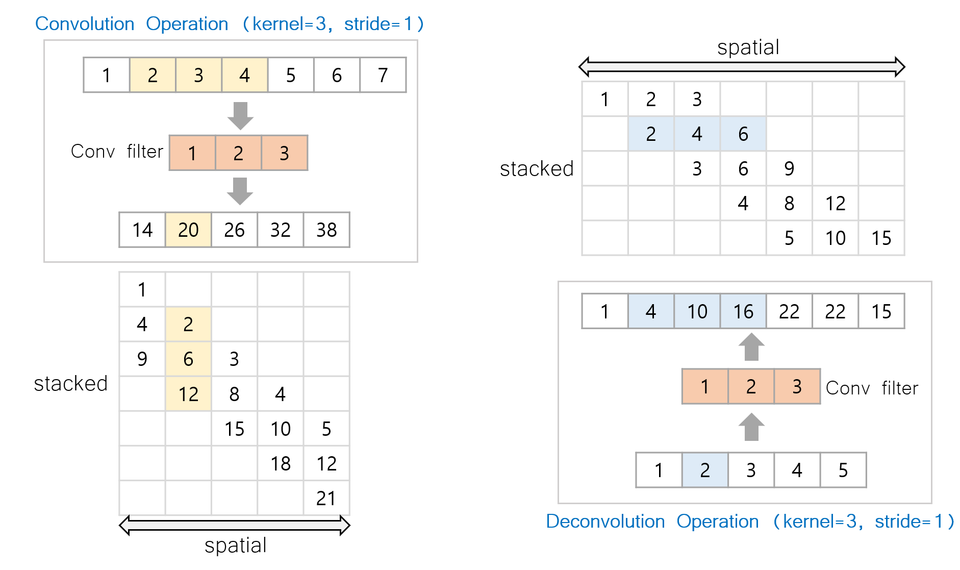
2.1 Convolution
Convolution 은 위치에 대해서 값을 중첩해서 전달하여, 픽셀에 강한 값이 있다면, 강한 정보가 그대로 전달된다. 반대로 약한 정보는 약한 상태로 전달된다. 또한 Stride 로 연속적인 값을 이루는 효과를 만들 수 있다. (Smoothing)
2.2 Deconvolution
Devolution 또한 값을 전달하며, 해당 위치에 대해서 값이 중첩되는 효과를 가진다. 여기서 문제가 되는 것은 입력값 [1,2,3,4,5] 에 대해서 값이 중첩되는 양이 고르지 않을 수 있으며, 입력 값이 동일하다면 Stride 에 따라서 큰 값을 가지는 필터에 의존적으로 값이 커질 수 있다는 것이다. 이로부터 Checkerboard 효과가 나타난다.
Figure 좌 : 값의 중첩
Figure 우 : Checkerboard 형태

Resize Convolution
Checkerboard 현상은 Kernel 사이즈가 Stride의 배수가 되면, (3 과 1 처럼) 중복되는 부분이 생기므로 Weight 에 의해서 나타난다고 한다. 그러나, 좀더 실용적인 해결 방법은 값을 전파하는 것보다 값을 응축하는 것이 쉽다는 것이다. Deconvolution이 역연산으로 이미지의 크기를 키워주는 것은 좋지만, Artifact 를 만들 가능성이 높기 때문에, Convolution 으로 이미지를 처리하는 방법을 제안한다. 그러나 Convolution을 하면 이미지의 사이즈가 커지지는 않기 때문에, 이를 위해서 Upsampling을 하고 Convolution을 하는 Resize-Convolution을 제안한다.
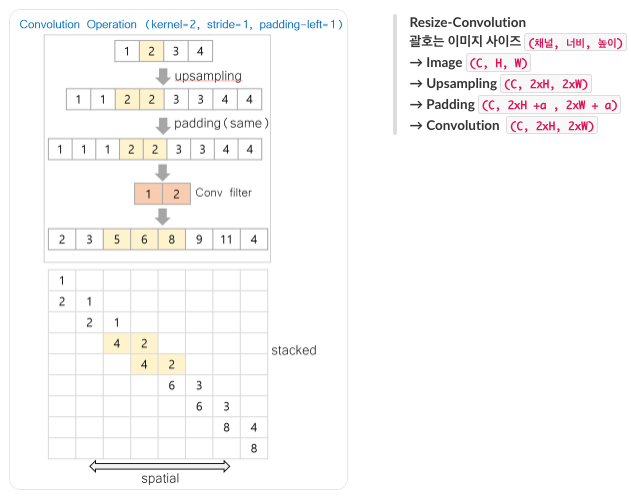
Experiment
실험으로는 Deconvolution이 얼마나 많이 포함되느냐에 따라서 Checkerboard 가 강해지는 지 확인하였고, Resize만 사용하는 경우, 기존 Checkerboard Artifact 가 사라지는 것을 확인하였다.

Conclusion
이 글에서 알 수 있는 것은 "연산이 가능한 것"과 "연산을 이해하는 것" 은 차이가 있다는 것이다. Deconvlution은 Convolution의 역연산으로 깔끔하게 이미지의 크기를 복원할 수 있지만, 실제로 그 과정에서 Inductive Bias 로 작용하는 값의 전파와 겹침 현상은 모델의 연산을 제대로 이해하지 못하고 사용하는 경우 발생하는 문제점으로 보인다.
따라서, 모델을 제대로 이해하고 사용하는 것이 중요하며, Artifact 의 생성이 단순히 학습의 부족이나, 데이터의 오류일수도 있지만, 모델의 Inductive Bias 로 인해서 생기는 결과물일 수 있음을 암시한다. 따라서 앞으로도 모델의 연산을 이해하고, 정보를 전달하는 방식을 이해하는 것이 중요해보인다. 추가적으로 전달되는 정보가 무엇인지도 안다면 모델을 해석하고 더 나은 모델을 만드는데 도움이 될 것으로 보인다.
'딥러닝' 카테고리의 다른 글
| [Circuits-CNN] Features, Circuits, and Activations [한국어] (2) | 2023.07.05 |
|---|---|
| Invariant 와 Equivariant 를 구분하는 방법 (1) | 2023.02.16 |
| Reinforcement Learning - Skill Discovery [스킬을 배우자] 중요한 것은 Mutual Information! (2) | 2023.02.13 |
| [실험] Pixel 제거로 InputAttribution 평가하기 (0) | 2023.01.19 |
| Pytorch Autograd Case Study (create_graph for gradient and retrain_graph for multiple backwards) (0) | 2022.11.07 |