
✍🏻 EXP Vision Transformer로 CIFAR 10 학습하기 [Korean]
ViT 결론 (TL;DR)
🔖 MNIST 는 학습이 아주 쉽다.
🔖 CIFAR 10 을 CrossEntropy로 Scratch 학습은 어렵다.
🔖 Pretrain 된 모델을 사용하면 1 epoch 만에 높은 성능을 보인다.
이 실험을 진행하기 전에 모델에 대해서 한 가지 믿음이 있었다.
학습데이터에 대해서 Loss를 줄이는 것은 Validation Loss를 어느정도 줄인다.
" Decreasing training loss ensures large portion of validation"
그러나 그렇지 않은 모델이 있음을 알게 되었다.
✍🏻Post Structure
1. ViT 설명
2. MNIST 학습
3. CIFAR 10 학습
4. Pretrained -> CIFAR 10 학습
먼저 이야기는 ViT를 학습시키는데서 시작한다. ViT는 Transformer 인코더 블록을 여러 개 쌓아올린 구조로, 각 블록은 Multi-head Attention과 MLP 그리고 Layer Normalization으로 이루어져있다. 모델은 input sequence에 대해서 어텐션 기반으로 학습을 진행한다. [그림참조]
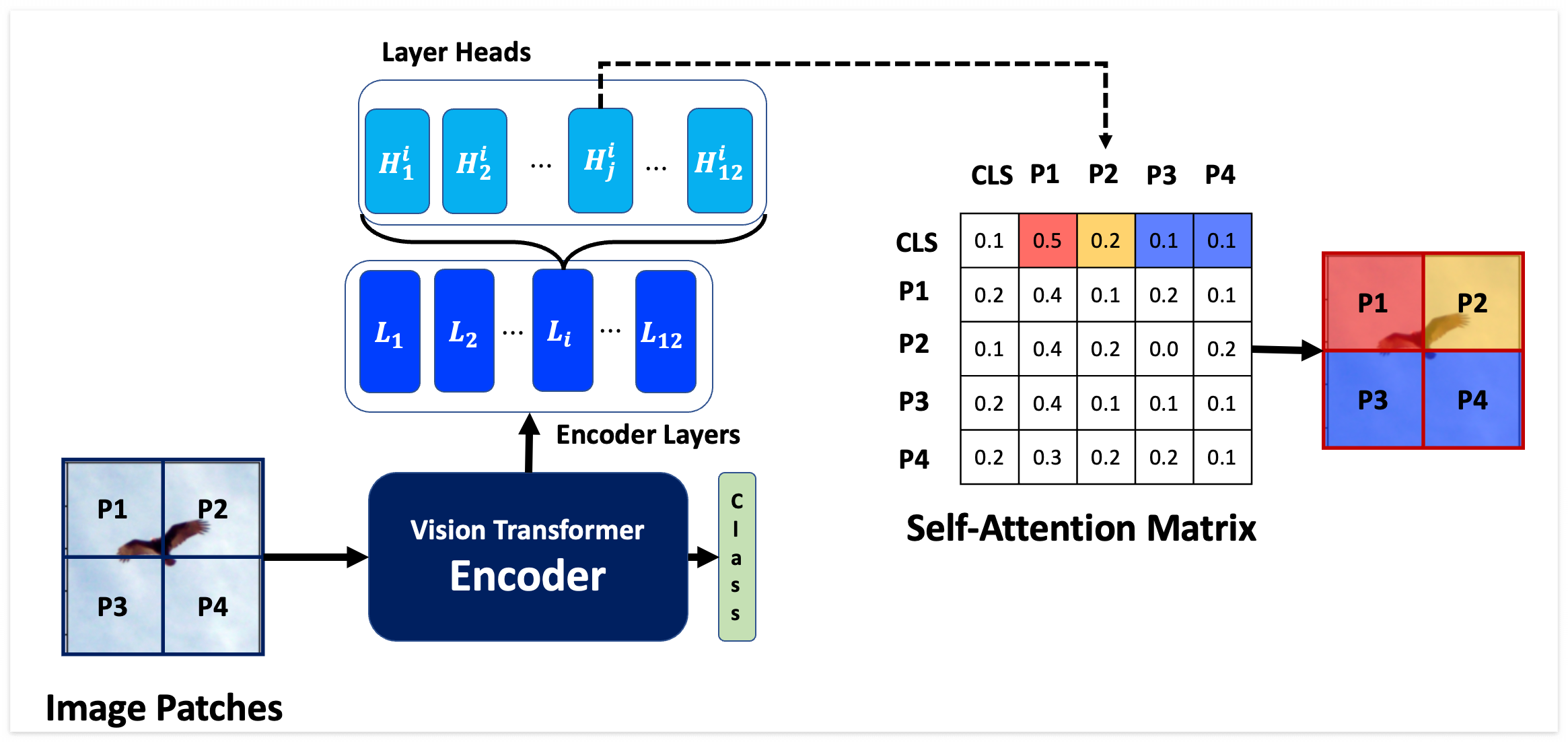
이러한 구조로부터 오는 ViT의 두 가지 특징은 다음과 같다.
- 더 이상 Translation Equivariance 하지 않는다❌. 서로 다른 패치들은 Positional Encoding으로 위치 정보가 추가되어 있다. (CNN에서는 Weight가 곱해질 때 위치에 대한 정보가 없다.)
- CNN은 Local한 Neighbor 정보를 기반으로 학습하는 Local Receptive Field 인 반면, ViT는 Attention 을 사용하는 Global Receptive Field 를 가진다.
논문 참조 : Transformers in Vision: A Survey (https://arxiv.org/abs/2101.01169)
그림 출처 : 내블로그 https://fxnnxc.github.io/blog/2022/exp_20/
CNN은 inductive bias가 심해서 학습이 쉽지만 자유도가 낮다. 반면에 ViT는 Attention을 모든 패치에 대해서 사용하기 때문에 학습의 자유도가 높다. 자유도가 높은 만큼, Classification에서는 CNN에 비해서 더 많은 샘플이 필요하다. 이러한 특징을 기반으로 두 개 모델을 결합한 모델을 제안하기도 하였는데, 여기서는 논외로 하고 Pure한 ViT 구조를 사용하였다.
논문 참조 : Convolution Vision Transformer (https://arxiv.org/abs/2103.15808)
🌊 Story 1: MNIST Training 학습

일단 기본적으로 ViT을 이해하기 위해서 MNIST 로 학습해봤다. 모델 구조는 Pytorch 에서 구현한 vit_16 모델 구조를 따랐다. 그냥 학습하면 심심하니, Layer 개수를 다양하게 설정해봤다.

실험 결과, Training Loss는 잘 줄어들었고, Validation Loss도 대부분의 3개 이상의 레이어에서는 99% 이상의 점수🦸🏻♂️를 얻었다. 그러나 하나의 레이어를 사용하는 경우, 제대로 학습하지 못하였다. 학습에 사용된 hyperparameter들은 다음과 같다.
image size : 56, patch_size: 4 , batch_size:32 learning rate : 1e-4
trainining for 200 epochs. StepLR with gamma 0.5 with every 100 epochs
hidden_dim : 128, dropout=0.5
(실험 결론) 이 실험으로 ViT를 학습하는데 있어서, 레이어 수를 많이 할 필요가 없으며, 3개 정도 이상의 모델이 데이터에 대해서 제대로 학습한다는 것을 알게되었다. 그리고 이야기는 CIFAR 10 을 학습하는데로 넘어간다.
참고로 ViT 계열은 12개 레이어를 가지는 것이 보통이다.
더 큰 모델은 블록도 많고 차원도 커서 파라미터가 훨씬 많다.
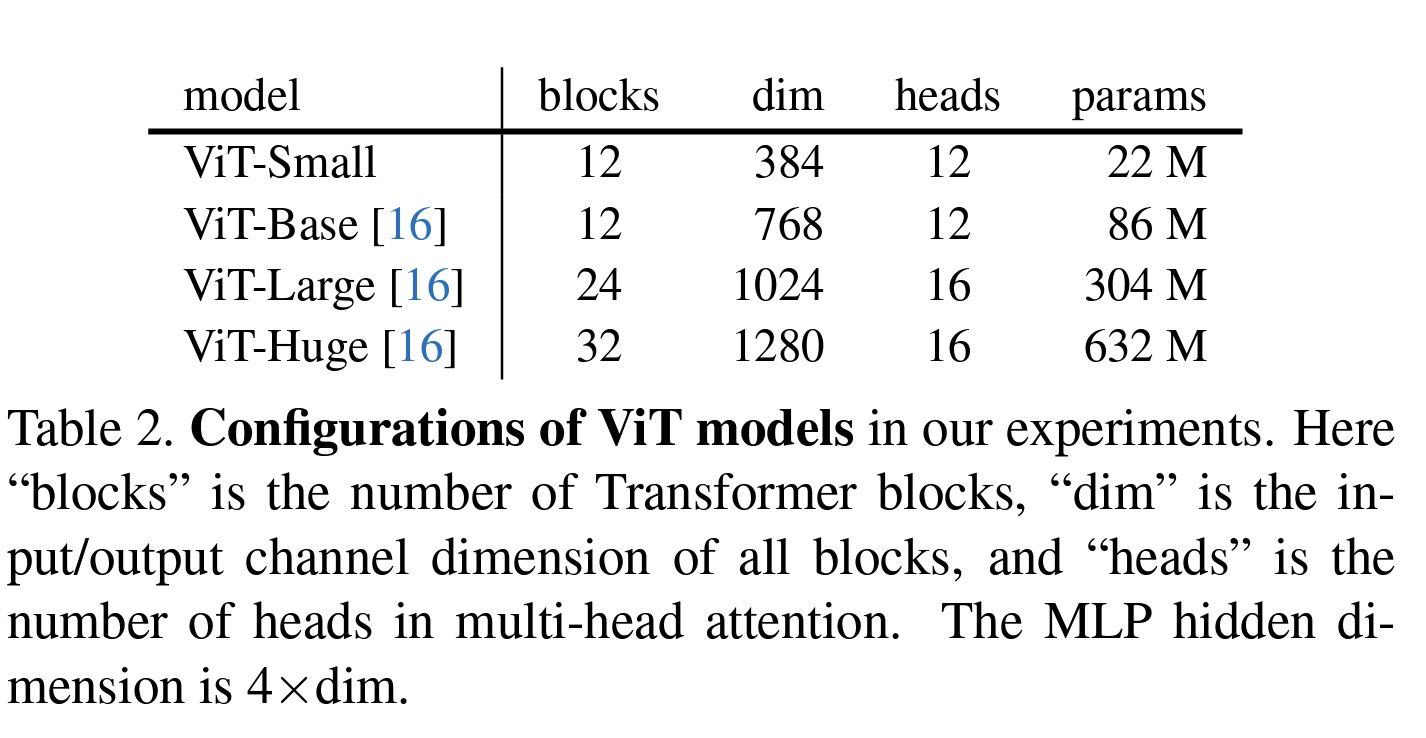
논문 참조 : An Empirical Study of Training Self-Supervised Vision Transformers
🌊 Story 2 : Cifar 10 학습 실패 스토리

MNIST와 동일한 모델구조로 이미지를 학습시켰다. 마찬가지로 다른 레이어 수에 대해서 검증하였고 결과는 별로 좋지 못하다.
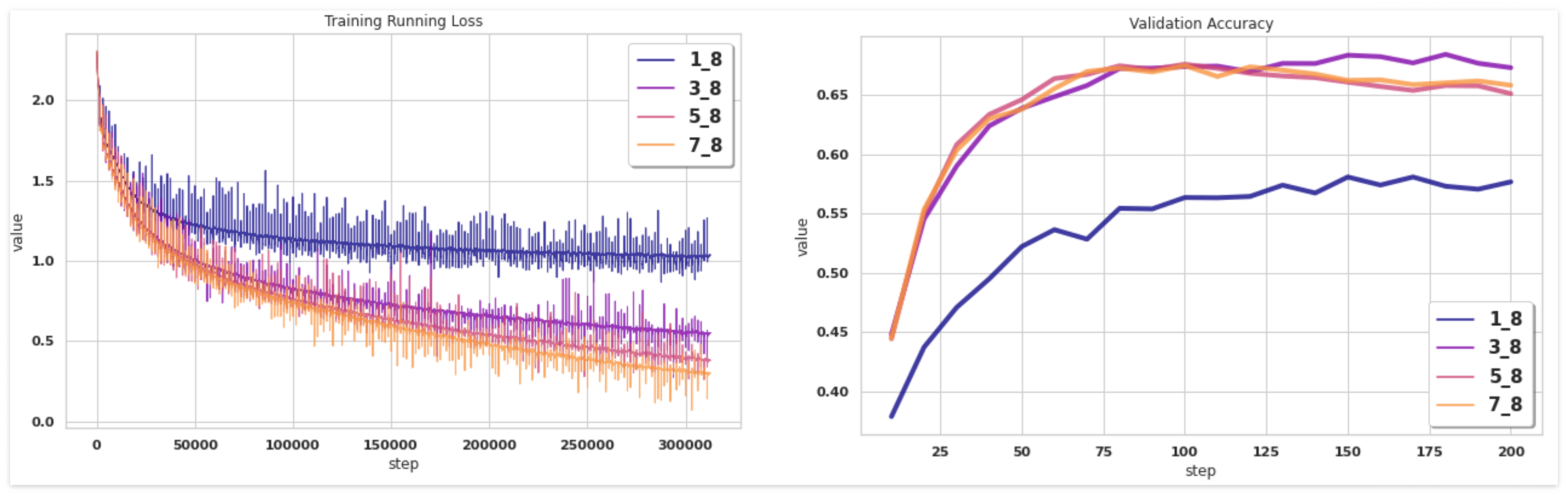
먼저 Training Loss를 보자. 헤드 개수를 늘릴수록 Loss는 빠르게 줄어든다. 이는 레이어가 많아짐으로 인해서 표현공간이 더 많은 정보를 담기 때문으로 보인다. Loss 가 0에 점점 가까워지는 것을 확인할 수 있다. 그러나 학습된 모델로 Validation을 진행하는 경우, 아주 엉망인 것을 확인할 수 있다. 이에 대해서 한 가지 가정은 Attention에 대해서 배우기 전에, Training 데이터에 대해서 Cheating 하는 방법을 배웠지만, 그게 Validation에는 통하지 않았기 때문으로 보인다. Attention은 기본적으로 이미지의 중요한 부분들에 대한 결단을 내려야 하는데, 해당 표현학습을 진행하기 전에 좀더 쉬운 방식을 배우는 것이다. 정확도가 0.7 을 넘지못하고, 더 이상 증가하지 않는다. 물론Regularization이나 Drop-out, Self-supervised learning 과 같은 여러가지 트릭을 적용할 수 있지만, 여기서는 단순히 Supervised loss 만 고려하였다.
이제 데이터의 구조를 더욱 잘 파악하고 있는 모델 파라미터 : 🦸🏻♂️PRETRAIN 모델🦸🏻♂️로 학습시켜보자.
또한 이제 레이어 개수를 Base model인 12 Ⅻ개로 맞추자.
🌊 Story 3 : Pretrained Model --> CIFAR 10
Pretrained Model 을 구할 수 있던 곳은 torchvision이다.
물론 HuggingFace에서도 제공하는데, torch를 사용하는 유저로서 더 사용하기 간단한 건 torchvision 이었다.
- 🟧 TorchVision : https://pytorch.org/vision/stable/models/generated/torchvision.models.vit_b_16.html
- 🤗 HuggingFace : https://huggingface.co/aaraki/vit-base-patch16-224-in21k-finetuned-cifar10
torchvision models 에는 기본적으로 3 종류의 Vision Transformer Weights 가 존재한다.
- SWAG로 ImageNet 1K - Finetuning🏋️♀️
- SWAG로 ImageNet1K (Frozen) + ImageNet 1K Finetuning🏋️♀️
- ImageNet 1K Scratch 학습 🏋️♀️
논문 참조 : SWAG(Revisiting Weakly Supervised Pre-Training of Visual Perception Models)
https://arxiv.org/abs/2201.08371
세 가지 모델 모두 데이터 ImageNet에 대해서 높은 성능을 보인다. 이 모델들을 가져와서 CIFAR 10 을 학습시켰다. 참고로 세 모델은 각각 Resize, CropSize, Patch Size가 다르다. 따라서 모두 다른 값을 사용해줘야 한다.
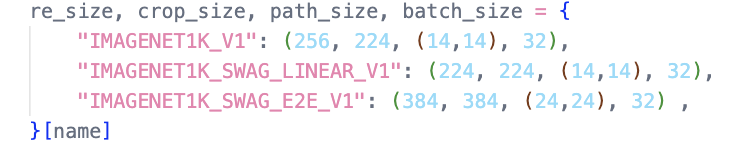
Fine Tuning 진행하기 🎯
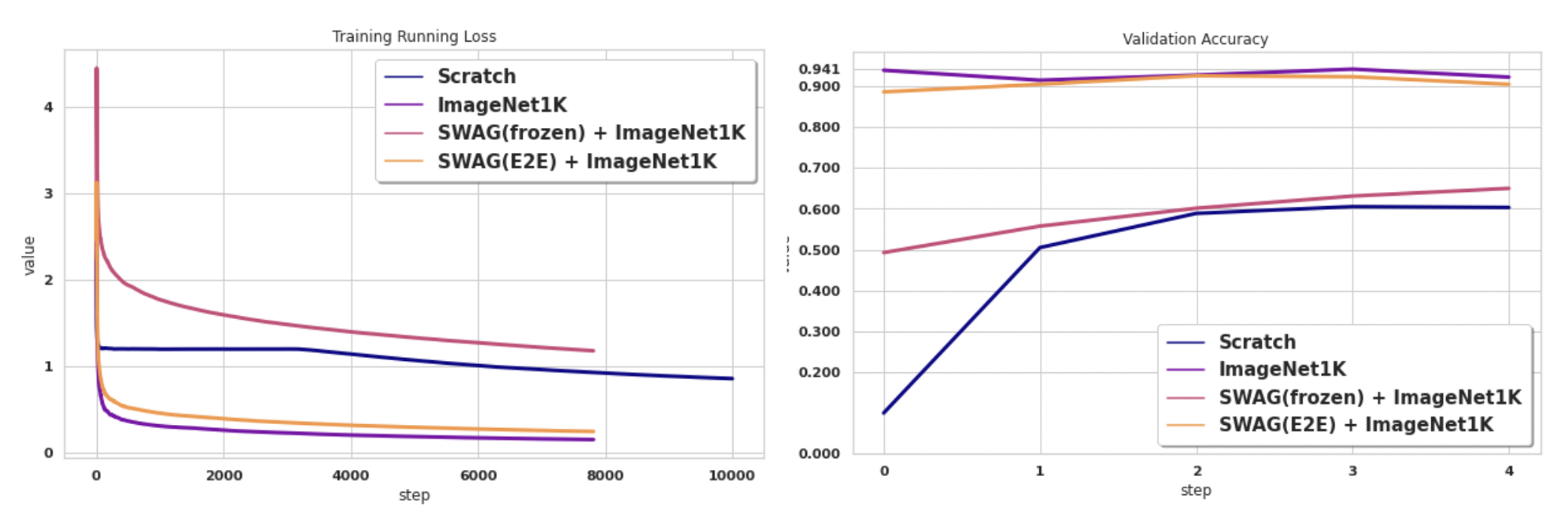
결과를 보면, 스크래치에 비해서 초반에 accuracy가 확 높아지는 것을 관찰할 수 있다. 또한 Frozen 되었던 Linear 모델은 사실상 ImageNet-1K에 대해서 튜닝시킨게 아니므로 Classification에 다시 학습하는데 시간이 소요되었다. 확실한 점은 Pretrain이 스크래치보다 나으며, Classification에 Bias 된 모델은 더 좋다는 것이다.
위의 실험과 마찬가지로 training loss를 줄이는 것은 쉬우나 Validation 의 성능을 높이는 것은 쉽지 않았다. 추가적으로 튜닝을 하면 학습을 더욱 잘 시킬 수 있으나, Validation에 overfitting될 거 같아서, 가장 간단한 Adam Optimizer + learning rate 0.0001 을 사용하였다. 단순히 CrossEntropy Loss로 성능을 더욱 높이는데는 한계가 있는 것 같다.
FINAL 결론 🔚
실험을 기획하면서 제일 궁금했던 것은 "Transformer 를 Supervised Learning으로 학습하면 어떻게 되는가" 였다. 실험적으로 보인 것은 스크래치로 학습하는 것이 안좋다는 것이다. 모델은 데이터에 대해서 의미있는 정보를 추출하는 것이 아니라, 단순히 학습데이터에 Overfitting 하는 방식으로 학습하는 것이었고, 이는 Self-Supervised Learning으로부터 배운 모델이 가지는 Global Receptive를 갖지 못한다는 것을 나타낸다.
모델을 학습할 때 보통 Trainining Loss 가 줄어들면 Validation도 줄어들 것이라고 예상하지만 ViT 모델은 그러한 기대를 과감하게 부수고 데이터에 대해서 Cheating 하는 것을 보여줬다. 결국 Pretraining 자체가 굉장히 중요하며, 이는 파라미터 Space에 대해서 의미있는 공간이 따로 존재하는 것을 나타낸다. 즉 Initialization / Supervised / Self-Supervised 에 대한 파라미터 공간이 다르기 때문에, 각 공간에서 시작해서 Downstream Task에 대한 학습을 진행한다면 모델은 그 공간의 근처에서 Loss를 최소화하는 것을 찾는다. 이러한 관찰은 모델의 파라미터들이 데이터를 최대한 알고있는지 검증하는 과정과 절차를 필요로 한다는 것을 알 수 있다.
요약 : 🟨 스크래치 < 🟨 Self-Supervised < 🟨 Classification Pretraining
'딥러닝' 카테고리의 다른 글
| Reinforcement Learning - Skill Discovery [스킬을 배우자] 중요한 것은 Mutual Information! (2) | 2023.02.13 |
|---|---|
| [실험] Pixel 제거로 InputAttribution 평가하기 (0) | 2023.01.19 |
| Pytorch Autograd Case Study (create_graph for gradient and retrain_graph for multiple backwards) (0) | 2022.11.07 |
| [논문 리뷰] OpenAI Learning to Play Minecraft with Video PreTraining (VPT) (0) | 2022.06.29 |
| Bayesian 1 - Think Bayesian approach (0) | 2021.02.06 |