
Last Updated on July 23, 2021
Bilingual Evaluation Understudy (BLEU)
딥러닝의 발달로 텍스트를 생성하는 Generative Model은 챗봇, 문서 요약등 다양한 분야에서 사용되고 있습니다. Generated Sentence를 평가하는 방식은 크게 BLEU 방식과 ROUGE 방식이 있습니다. 여기서는 BLEU 와 이를 계산할 파이썬 라이브러리를 소개합니다. (TMI: BLEU 는 블류라고 읽어주시면 됩니다)
Generative Model은 주로 Supervised Learning 방식으로 정답이 되는 Reference Sentence가 있습니다. 모델로부터 생성되는 문장을 Generated Sentence 그리고 비교하는 정답을 Reference Sentence라고 합니다. 그림으로 나타내면 다음과 같습니다.
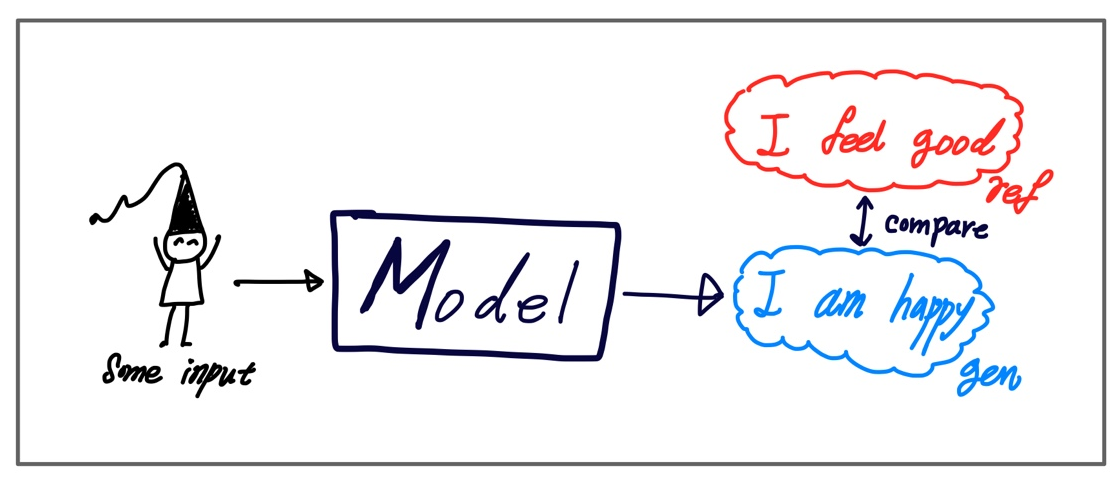
생성된 문장을 평가하는 방식은 크게 2가지가 있습니다.
- Reference Setence의 단어가 Generated Sentence에 포함되는 정도 → ROUGE
- Generated Sentence의 단어가 Reference Sentence에 포함되는 정도 → BLEU
각각을 식으로 나타내면 다음과 같습니다.
- ROUGE : $\#\{ w_{ref} \in S_{gen} | w_{ref} \in S_{ref} \} / |S_{ref}|$
- BLEU : $\#\{ w_{gen} \in S_{ref} | w_{gen} \in S_{gen} \} / |S_{gen}|$
예를 들어서, 모델이 생성한 문장이 "I was generated by the model" 이었고 실제 정답은 "I was referenced by human" 이라고 한다면 "i", "was" "by"는 두 문장에 공통으로 들어있게 됩니다. 따라서 BLEU와 ROUGE는 다음과 같이 구할 수 있습니다.
- ROUGE: $\#\{ w_{ref} \in S_{gen} | w_{ref} \in S_{ref} \} / |S_{ref}| = 3/5$
- BLEU: $\#\{ w_{gen} \in S_{ref} | w_{gen} \in S_{gen} \} / |S_{gen}| = 3/6$
BLEU값은 0이 가장 작고, 1이 가장 큰 값입니다. ROUGE score는 주로 Text Summarization에서 사용되고 BLEU Score는 일반적으로 Machine Translation에서 사용됩니다.
Reference가 되는 문장은 하나가 아니라 여러 개일 수 있습니다. 예를 들어서, "I was happy" 라는 문장을 번역하는 모델이 있을 때, 정답에 "나는 행복했다.", "나는 행복했었다.", "행복했다,, 나는" 이라고 여러 개의 정답이 있을 수 있습니다. 따라서 BLEU를 계산할 때는, 이러한 중복된 Reference에 대해서 고려해줘야 합니다. BLEU는 단어가 Reference 중에 한 곳에라도 포함된다면 정답인 걸로 셉니다.
Code
Python의 nltk 라이브러리를 사용하면 BLEU를 쉽게 계산할 수 있습니다.
from nltk.translate.bleu_score import sentence_bleu
Ex1)
첫 번째 예시는 Reference 문장이 Generated 된 문장과 완벽하게 일치하는 경우입니다. 이 경우 BLEU score는 가장 높은 값인 1.0 이 나옵니다.
reference = [["this", "is", "the", "sample"]]
candidate = ['this', "is", "the", "sample"]
score1 = sentence_bleu(reference, candidate, weights=(1, 0, 0, 0)) # 1.0Ex2)
두 번째 예시는 Generated 문장에서 일치하는 단어가 각각 다른 Reference에 있는 경우입니다. 이 경우에도 BLEU score는 가장 높은 값인 1.0 이 나옵니다.
reference = [["this", "is", "the", "good", "choice"],
["it", "is", "a", "sample"]]
candidate = ['this', "is", "the", "sample"]
score2 = sentence_bleu(reference, candidate, weights=(1, 0, 0, 0)) # 1.0Ex3)
마지막은 Generated 문장의 단어가 Reference에 포함되지 않은 경우입니다. 이 경우는 a 하나가 reference에 들어있지 않기 때문에 4/5가 나옵니다.
reference = [["this", "is", "the", "sample"],
["this", "is", "the", "good","sample"]]
candidate = ['this', "is", "a", "good", "sample"]
score3 = sentence_bleu(reference, candidate, weights=(1, 0, 0, 0)) # 0.8print(" Exact Match :" , score1) # 1.0
print(" Two References:" , score2) # 1.0
print("Not included word : ", score3) # 0.8따라서 Reference가 많다면 BLEU score는 높아질 수밖에 없습니다.
Ex4)
만일 문장 하나가 아니라 여러 개의 문장(코퍼스 Corpus)에 대해서 한 번에 계산하고 싶다면 다음 코들 이용하면 됩니다.
from nltk.translate.bleu_score import corpus_bleu
reference = [[["this", "is", "a", "sample"]],
[["another", "sentence"], ["other", "sentence"]]]
candidate = [['this', "is", "a", "sample"],
['just', "another", "sentence"]]
score4 = corpus_bleu(reference, candidate, weights=(1, 0, 0, 0))
print("Multiple Sentence : ", score4) # 0.77
코드를 자세히 보면 weights=(1,0,0,0) 으로 표시된 부분을 확인할 수 있습니다. BLEU를 계산할 때, 단순히 단어의 등장으로 센다면, 단어의 순서에 관계없게 동일한 BLEU를 가지게 됩니다. 실제로 아무 의미 없는 문장인 "I happy was" 가 "I was happy" 와 동일한 값을 가지게 됩니다. 그래서 BLEU에서는 단어 1개인 1-gram 방식을 넘어서, 2,3,4-gram 방식을 모두 사용해서 값을 구하는 방식을 취합니다. 여기서 weight는 각 n-gram에 대한 가중치를 나타냅니다.
만일 1,2,3,4-gram에 대해서 동일한 가중치를 두고 싶다면,
weights=(0.25, 0.25, 0.25, 0.25) 로 설정해주시면 됩니다.
본 포스팅은 BLEU에 대한 Posting을 참조했습니다.
https://machinelearningmastery.com/calculate-bleu-score-for-text-python/
'딥러닝 > 자연어(NLP)' 카테고리의 다른 글
| 🧐 Sequence Labeling with Tagging (0) | 2021.05.24 |
|---|---|
| NLP의 모든 분야 탐색 (Update 중) (0) | 2021.02.19 |
| [Fairseq 1] Robert Pretrain 코드 돌리기 (0) | 2021.02.16 |
| [Paper Short Review] Do sequence-to-sequence VAEs learn global features of sentences (0) | 2021.02.13 |
| Text Summarization 분야 탐색 (0) | 2021.02.05 |