
Ray-RLLib
1 Ray의 전체적인 구조
Ray는 분산처리를 위한 프로젝트로 파이썬으로 작성되었습니다. 이를 바탕으로 시간이 오래 걸리는 강화학습을 더욱 효율적으로 할 수 있습니다.
강화학습 라이브러리로 유명한 OpenAI Gym과도 연동된다는 점은 Ray로 학습을 해야 하는 중요한 이유입니다.
- 이러한 라이브러리를 만든 목적도 OpenAI Gym형태의 Envrionment에 대해서 RLlib를 적용시켜서 학습하는 것.

2 RLlib
RLlib에서 바꿀 수 있는 부분은 다음과 같다. 해당 부분에 대해서 사용자가 커스터마이즈 할 수 있다.
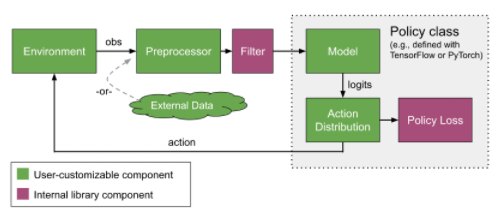
2. Policy
Agent를 조종하기 위한 Policy 구조.
- single agent에 대해서 하나의 Policy를 할당.
- Multi Agent 대해서 하나의 Policy를 할당.
- MultiAgent에 대해서 각각 다른 Policy를 할당.
최종적인 목적은, MultiAgent Setting에서 각각 다른 Policy를 가지고 행동하는 것이다.

3 Sample Batches
Episode에 대해서 Trajectory를 축척한다. 모든 정보는 이곳에 저장된다. 만일 MultiAgent 환경이라면, 각각의 Agent마다 Sample Batch를 가지게 된다.
{ 'action_logp': np.ndarray((200,), dtype=float32, min=-0.701, max=-0.685, mean=-0.694),
'actions': np.ndarray((200,), dtype=int64, min=0.0, max=1.0, mean=0.495),
'dones': np.ndarray((200,), dtype=bool, min=0.0, max=1.0, mean=0.055),
'infos': np.ndarray((200,), dtype=object, head={}),
'new_obs': np.ndarray((200, 4), dtype=float32, min=-2.46, max=2.259, mean=0.018),
'obs': np.ndarray((200, 4), dtype=float32, min=-2.46, max=2.259, mean=0.016),
'rewards': np.ndarray((200,), dtype=float32, min=1.0, max=1.0, mean=1.0),
't': np.ndarray((200,), dtype=int64, min=0.0, max=34.0, mean=9.14)}
4 Trainer
데이터 수집과 훈련은 동기화를 통해서 진행된다. 병렬처리를 하게 된다.
어느정도 훈련된 모델로 데이터를 새로 수집하고 그 데이터를 가지고 다시 훈련을 진행하고... 반복적으로 시행.

References
'딥러닝 > 강화학습(RL)' 카테고리의 다른 글
| [Analyse RLLib] 4. RLlib CallBacks (0) | 2021.02.26 |
|---|---|
| [Analyse RLLib] 3. Train Model with Ray Trainer (0) | 2021.02.26 |
| [Analyse RLLib] 2. RLlib 기본 훈련 코드 돌리기 (0) | 2021.02.26 |
| MARL-DRONE (0) | 2020.12.31 |
| MARL - MADDPG 이해하기 (0) | 2020.12.20 |