
트랜스포머가 훈련이 잘 안되는 이유와 그걸 가능하게 만든 방법.
Abstract
- 인코더 60층, 디코더 12층 까지 쌓아서 트랜스포머를 훈련시키는데 성공했습니다.
- $\color{blue}{WMT14 English-French}$ 밴치마크에서 SOTA를 찍었습니다. (43.8BLEU and 24.4 BLEU with back-translation)
1 Introduction
- Deeper model은 더 더양한 표현을 소화할 수 있습니다.
- 현재 NMT에서 SOTA인 모델의 사이즈는 Enc6/Dec12밖에 되지 않습니다.*
- Optimization Challenge : 각 층의 분산이 쌓여서 훈련이 불안정하고 발산하게 됩니다.
- 최근에 나온 초기화 방법인 ADMIN방법으로 Variance problem을 해소합니다.
즉, ADMIN 초기화 방법으로 NMT를 성공적으로 학습시키고 SOTA를 찍은 게 이 논문의 기여입니다.
2 Background
- Transformer equation

$$
x_i = f_{LN}(x_{i-1}+f_{ATT}(x_{i-1}))\\
x_{i+1} = f_{LN}(x_{i}+f_{FF}(x_{i}))\\
x_{i} = f_{LN}(x_{i}+f_{i}(x_{i-1}))\\
where\
f_{LN}(\cdot) : Layer Normalization\\
f_{ATT}(\cdot) : Multihead attention\\
f_{FF}(\cdot) : Feed Forward
$$
- Optimization difficulty
Vanishing gradient : LN이 완화를 해주지만, 디코더와 인코더의 아래 층에 gradient flow가 약한 것은 문제가 됩니다.- 해결책으로 pre-LN을 할 수 있고 이 방법으로 30층까지는 훈련을 안정적으로 진행할 수 있습니다.
- 하지만 post-LN이 훈련된다면, pre-LN보다 성능이 좋은 경우가 많습니다. 따라서 논문에서는 post-LM을 안정적으로 훈련하고자 하였습니다.
3. Initialization Technique
$$
x_{i} = f_{LN}(x_{i-1}\cdot w_i+f_{i}(x_{i-1}))
$$
where $w_i$ is a constant vector that is element-wise multiplied to $x_{i-1}$
$x_{i-1}$부분과 $f_i(x_{i-1})$의 magnitued가 다른 게, 불안정한 훈련의 원인으로 봤습니다. 따라서 $w_i$ 벡터를 이용해서 두 개의 magnitude 차이를 줄여주고자 했습니다.
ADMIN
- Profiling phase
- 모델 파라미터를 랜덤하게 초기화 합니다. $w_i=1$
- one-step forward를 진행하고 각 층에 대하여 residual branch의 분산 $\color{red}{Var[f(x_{i-1})]}$을 계산합니다.
- training phase
- $w_i = \sqrt{\sum_{j<i}{Var[f(x_{j-1})]}}$로 고정합니다.
- After training finish
- $w_i$는 더 이상 필요가 없습니다. 원래 기본 트랜스포머를 사용합니다.
4. Experiments
Data
- WMT'14
- English-French
- training sentences: 36M
- subword vocabrary : 40K
- valid : provied
- test : newstest14
- English-German
- training sentences: 4.5M
- subword vocabrary : 32K
- valid : newstest13
- test : newstest14
- English-French
- Model
- FAIRSEQ
- word embedding : 514-dim
- model size : 2048 (dimension)
- heads : 8
- number of layers : [6/6, 60/12]
- optimization : RAdam
- FAIRSEQ
Result
모델의 성능을 평가하는 세 가지 부분에 있어서 baseline을 뛰어 넘었습니다.

훈련과 Valid 데이터 있어서 PPL을 기존 모델보다 더 낮췄습니다.
Default 모델이 Train에서 PPL을 더 이상 줄이지 못했던 부분을 ADMIN으로 모델의 파라미터를 초기화한 모델은 0에 가깝게 줄일 수 있었는데, 이 차이가 Validation set에도 그대로 효과를 봤습니다.

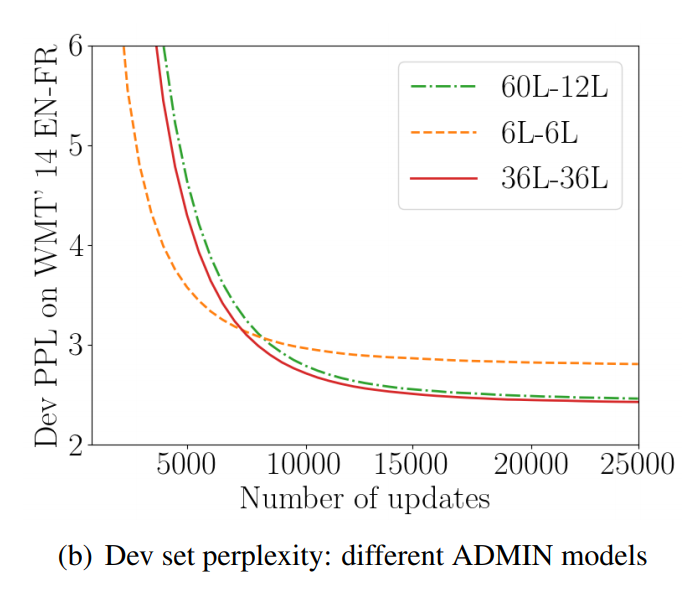
ADMIN 초기화 방식은 층이 깊어져도 효과가 뛰어남을 확일 할 수 있습니다.
따라서 층을 늘려도 안정적으로 학습이 가능합니다.
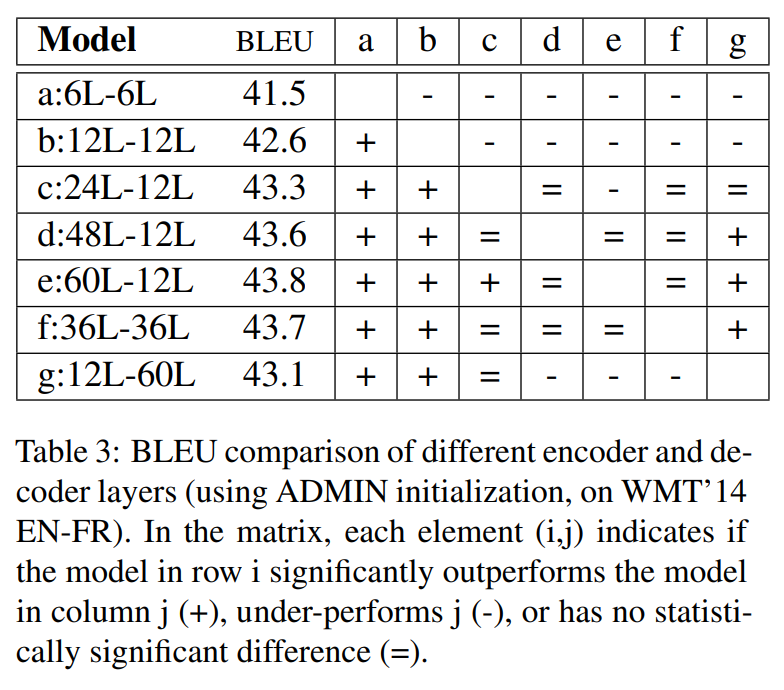
단어 빈도 수와, 문장 길이에 대해서 얼마나 모델이 정확하게 번역하는지 확인하는 부분에서도 모든 분류에 대해서 6/6모델의 성능을 뛰어넘었습니다.

References
'딥러닝 > 자연어(NLP)' 카테고리의 다른 글
| Transformer와 인간의 뇌 구조 (0) | 2021.02.03 |
|---|---|
| Byte Pair Encoding 방법 (0) | 2021.02.02 |
| Transformer 모델 학습은 생각보다 어렵다. (0) | 2021.01.19 |
| 나만의 자연어처리 공부방법 (0) | 2020.08.24 |
| About NLP (0) | 2020.07.23 |